檔案6:L11301 機器學習基本原理(100題)
共100題(難度比照初級樣題)
1. 出題頻率/重要性:★★★
由大綱出題:Yes(參考:初級大綱.txt - L11301 機器學習基本原理)
機器學習 (Machine Learning) 最核心的意義是什麼?
答案:C
解析:機器學習能根據資料學到模型或規則,在未知情境下做預測或分類等任務。
2. 出題頻率/重要性:★★
由講義出題:Yes(參考:01_AI基礎理論_講義.pdf 第32頁)
監督式學習可再分為「分類 (Classification)」與哪一種類型?
答案:C
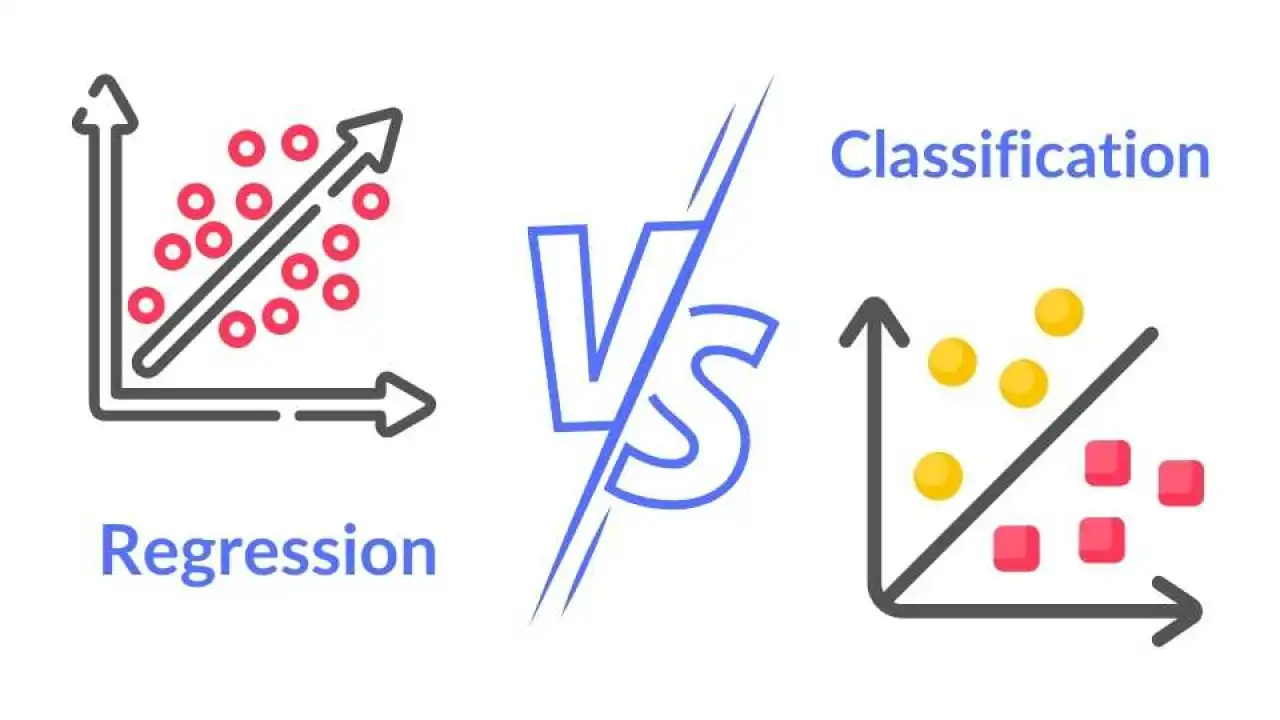
解析:監督式學習分為分類(目標為離散)與迴歸(目標為連續數值),是最常見的兩大類。
3. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
下列哪個任務最有可能使用「非監督式學習」?
答案:A
解析:非監督式學習沒有標籤,如分群。其餘皆屬監督式(目標已知)或時間序列預測。
4. 出題頻率/重要性:★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第12頁)
「強化式學習 (Reinforcement Learning)」與監督式學習最大差異是?
答案:B
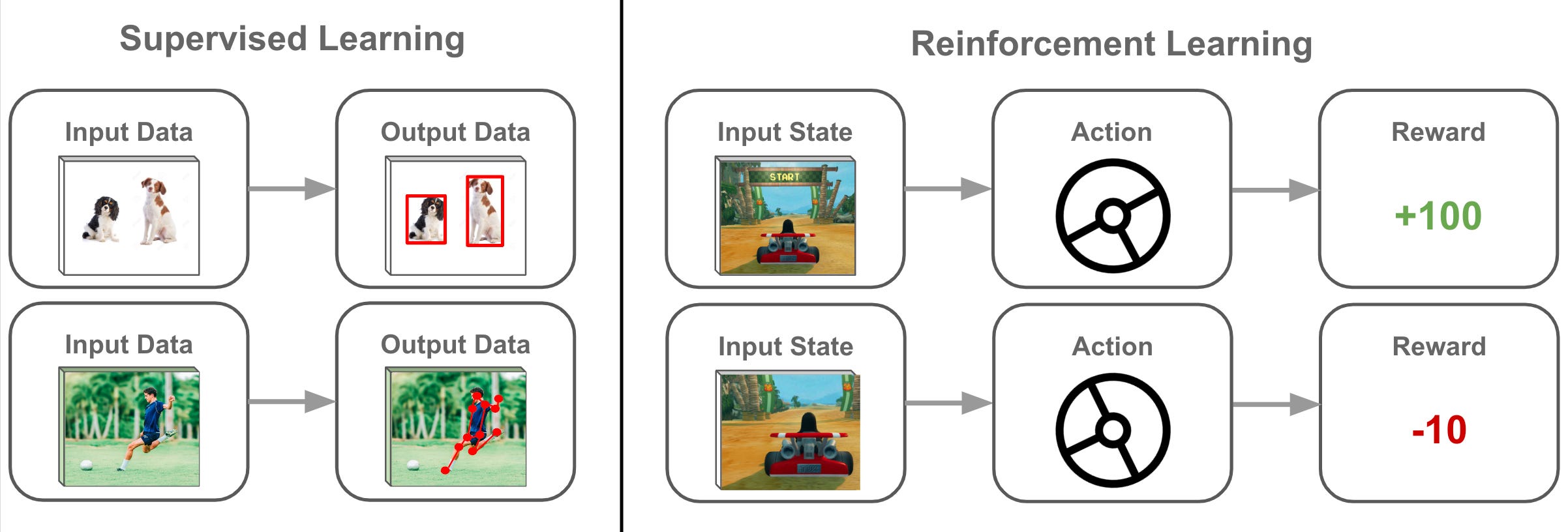
解析:強化式學習在互動環境中累積獎勵,非一次性給出正確標籤。
5. 出題頻率/重要性:★★★
由大綱出題:Yes(參考:初級大綱.txt - L11301 機器學習基本原理)
機器學習流程的關鍵步驟依序為?
答案:A
解析:典型機器學習流程先有資料,再做清理/特徵,再來建立模型、評估效果,最後部署應用。
6. 出題頻率/重要性:★
由講義出題:Yes(參考:01_AI基礎理論_講義.pdf 第40頁)
當模型在訓練資料表現良好,卻在測試資料表現很差,通常稱為?
答案:A

解析:過擬合代表模型過度貼合訓練集,無法泛化。
7. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
欠擬合 (Underfitting) 常意味著?
答案:C
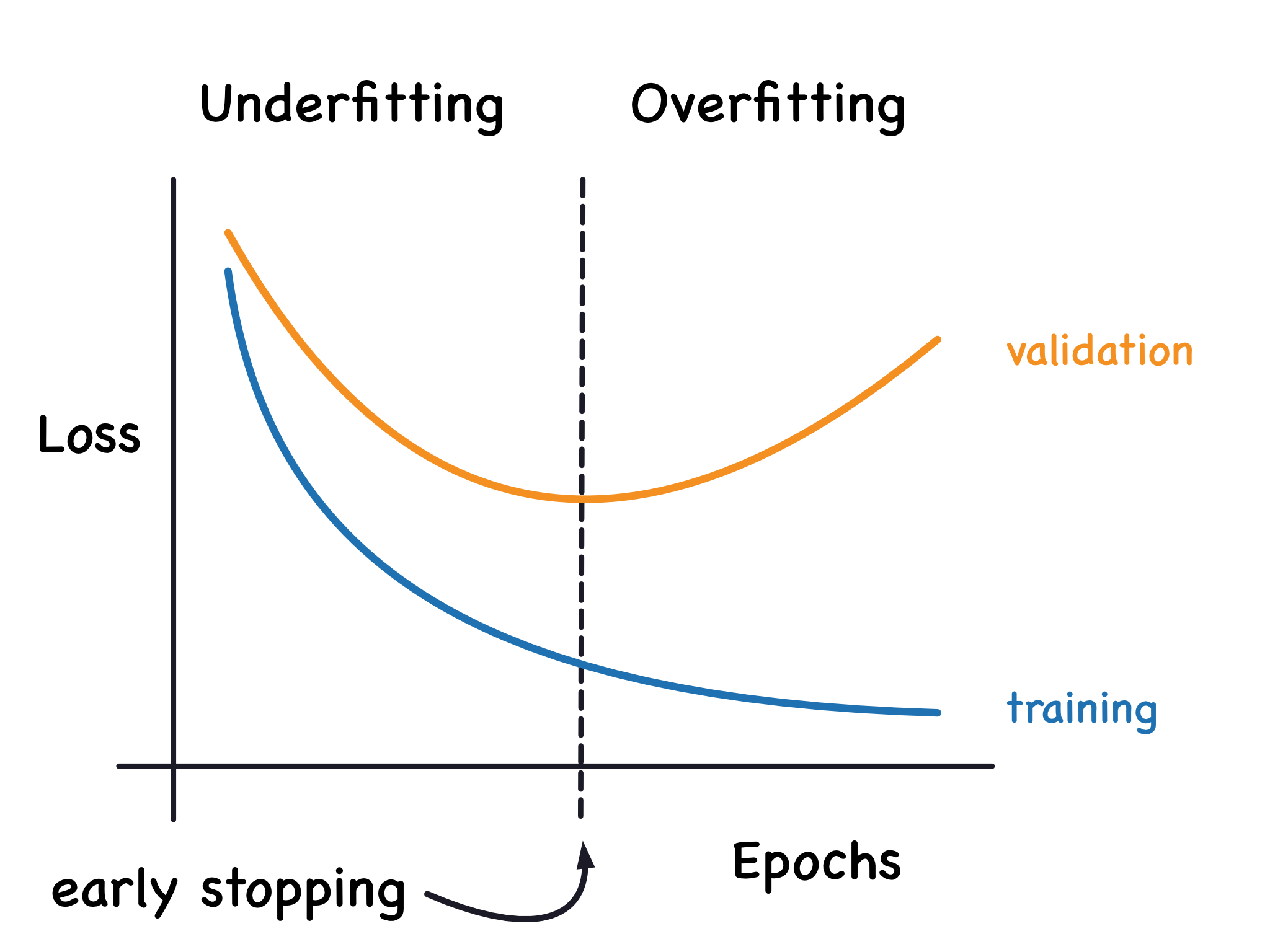
解析:欠擬合是模型表現不佳,可能特徵不足或模型表達能力太弱。
8. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第25頁)
下列何者屬於「決策樹 (Decision Tree)」的優點?
答案:A
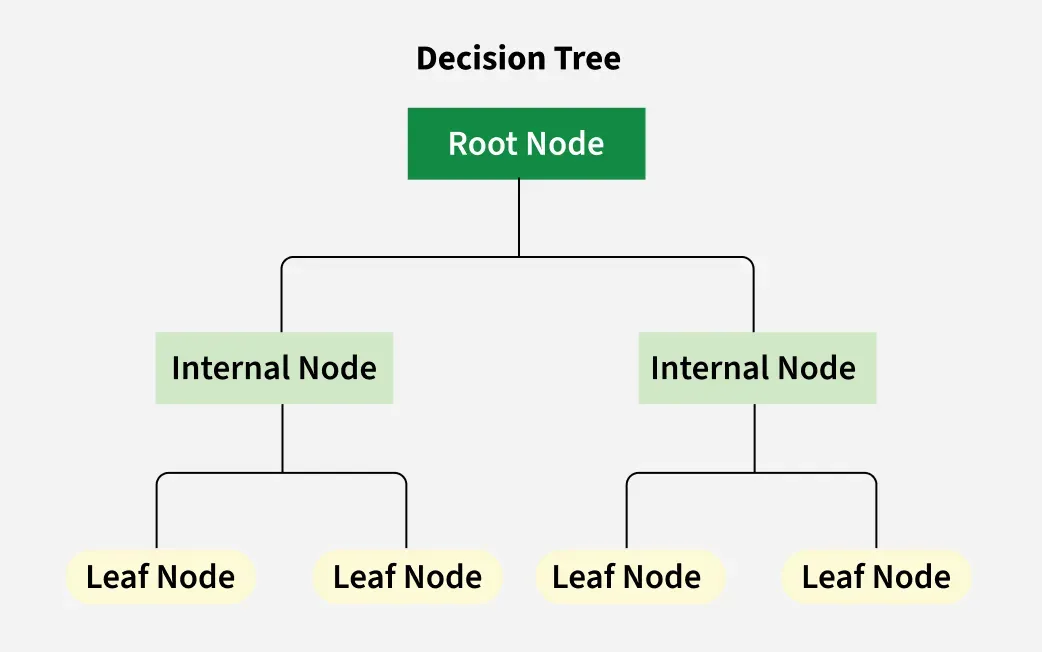
解析:決策樹的可解釋性高,規則像 if-else,但易過擬合,常搭配集成方法(如隨機森林)。
9. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
「隨機森林 (Random Forest)」相較於單一決策樹,有何優勢?
答案:A
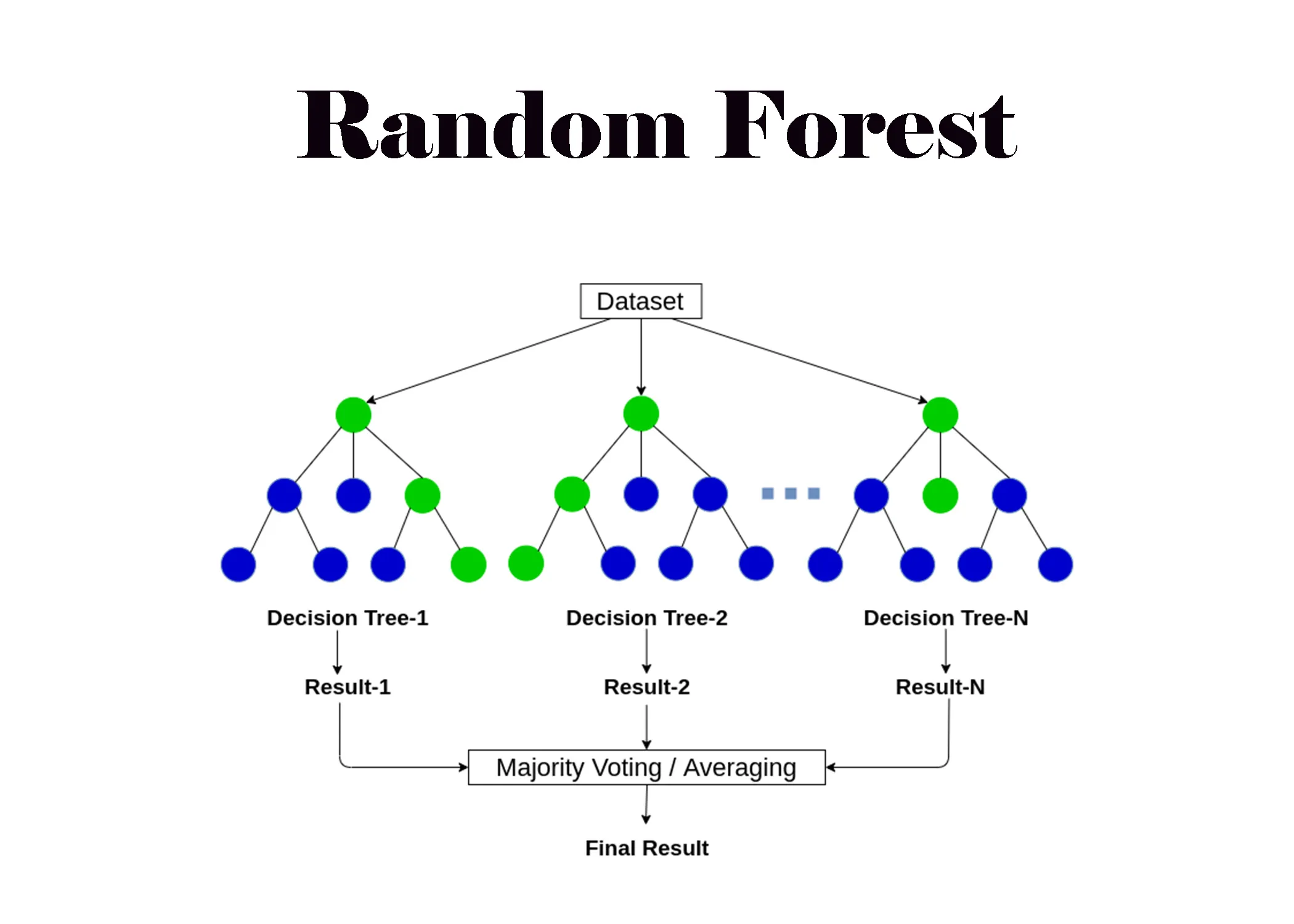
解析:隨機森林在每棵樹訓練使用部分資料與特徵,最終投票或平均,可減少樹的高度過擬合。
10. 出題頻率/重要性:★
由大綱出題:Yes(參考:初級大綱.txt - L11301 機器學習基本原理)
常見的「線性迴歸 (Linear Regression)」假設為何?
答案:B
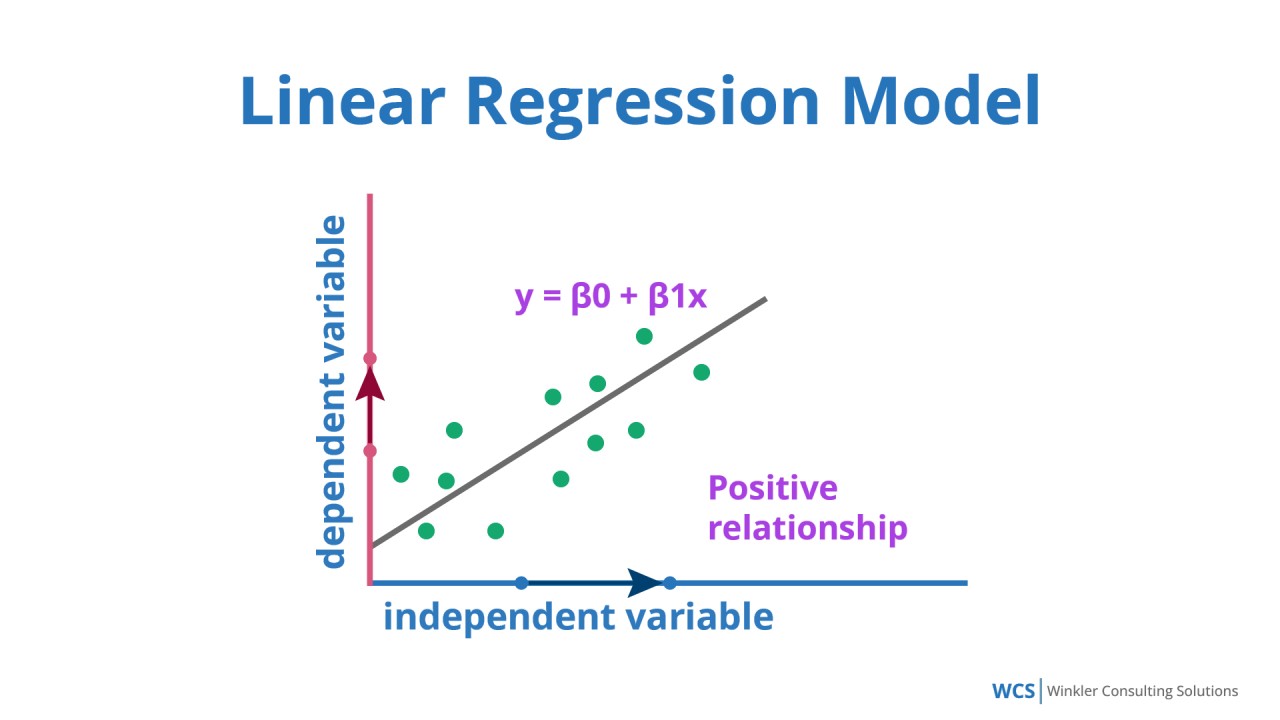 "
"
解析:線性迴歸基本模型為 y = w1x1 + … + wnxn + b,假設輸出可視作線性組合。
"
11. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
下列哪個度量較常用來評估迴歸模型的誤差?
答案:A
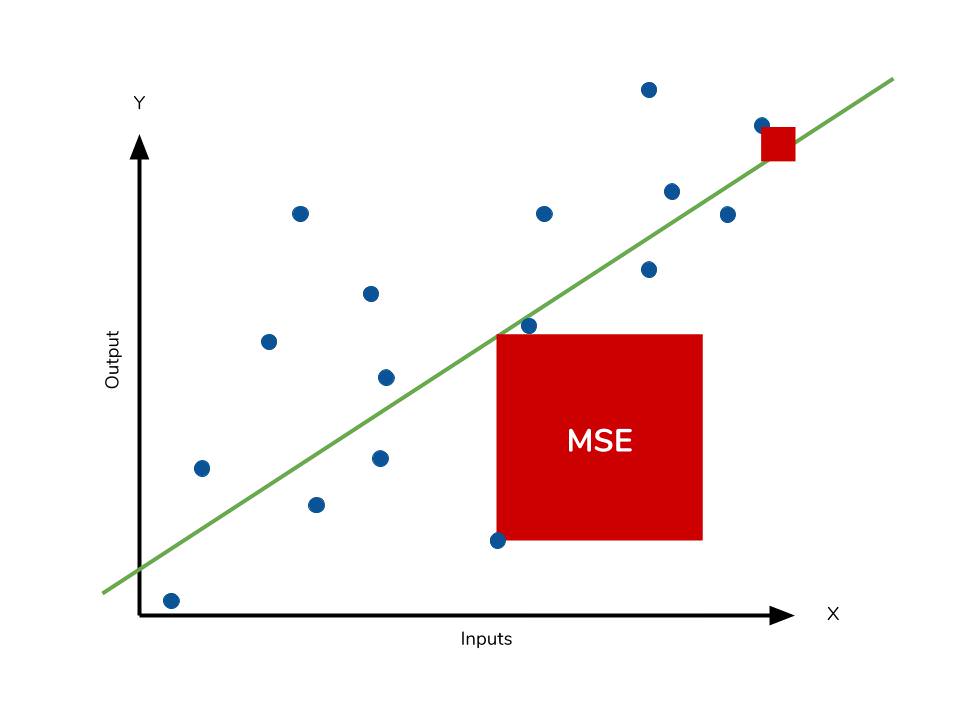
解析:MSE、MAE、RMSE 是最常見迴歸模型評估方式,Accuracy、AUC、F1-score 則多用於分類。
12. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第35頁)
為何要分割訓練集與測試集?
答案:C
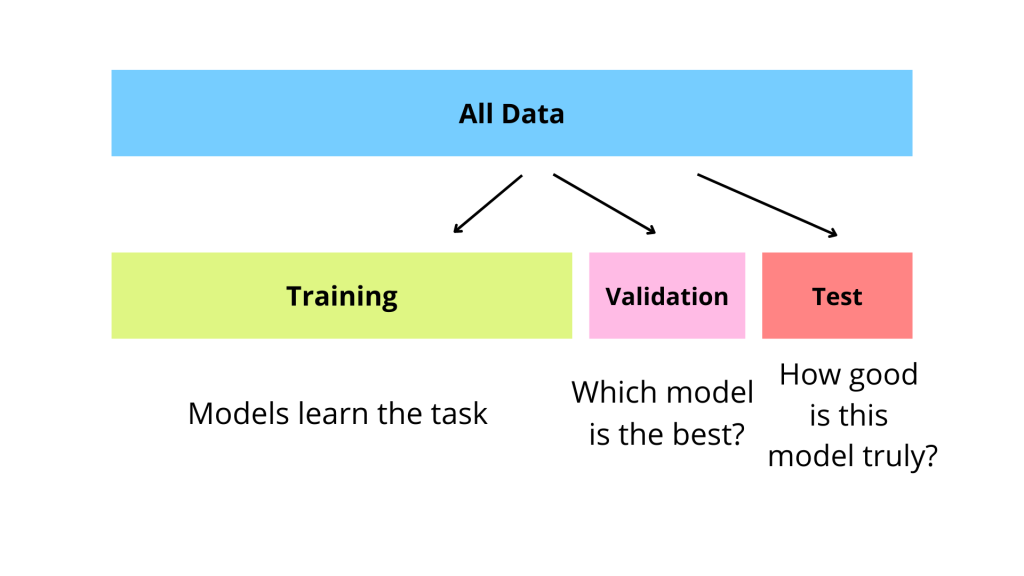
解析:測試集是用於最終檢驗模型對新資料的表現,防止過擬合狀態下的假性高分。
13. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
何謂「學習率 (Learning Rate)」在迴歸或神經網路訓練中的角色?
答案:A
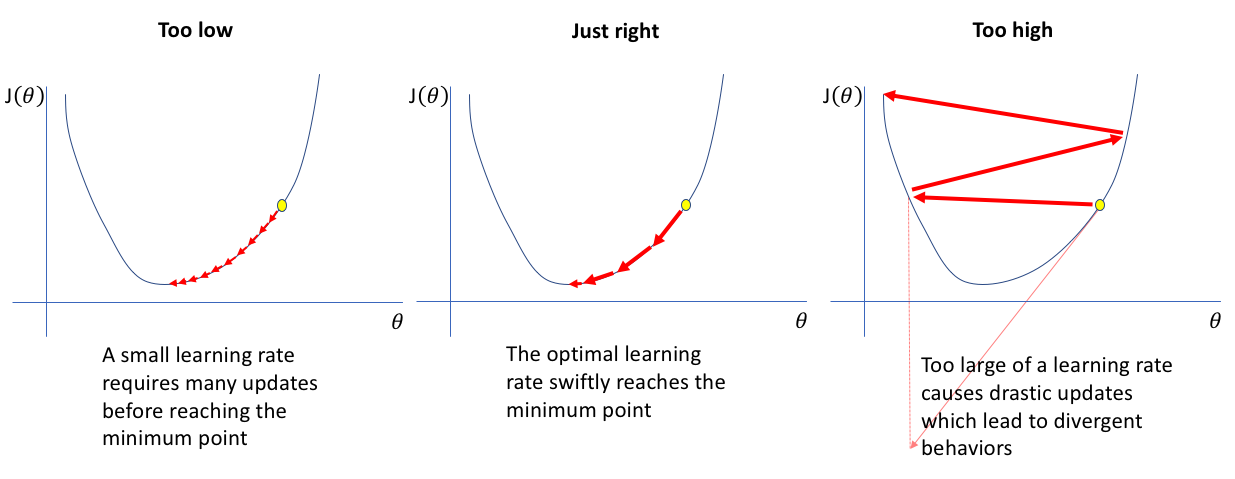
解析:學習率決定梯度下降一步走多遠,需適度調整才能穩定收斂。
14. 出題頻率/重要性:★★
由講義出題:Yes(參考:01_AI基礎理論_講義.pdf 第45頁)
「批量梯度下降 (Batch Gradient Descent)」與「隨機梯度下降 (SGD)」差異?
答案:A
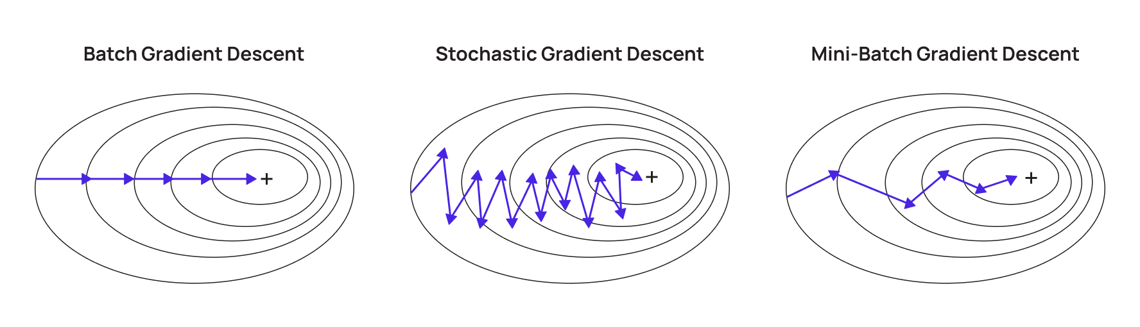
解析:批量梯度下降計算更精確但可能較慢,SGD每次更新速度快但帶隨機性。
15. 出題頻率/重要性:★★★
由大綱出題:Yes(參考:初級大綱.txt - L11301 機器學習基本原理)
下列哪些方法常用來避免模型過度擬合?
答案:B
解析:正則化可壓縮權重避免過大,Data Augmentation 提高資料多樣性,Early Stopping 根據驗證集判斷訓練是否過度。
16. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
在資料集中若不同類別分佈嚴重不平衡,預測模型可能?
答案:C
解析:嚴重不平衡時,模型可能只猜最多類別;可用 Oversampling/Undersampling/SMOTE 等策略平衡。
17. 出題頻率/重要性:★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第40頁)
何謂「偏差 (Bias)」與「變異 (Variance)」在模型誤差分解中的含意?
答案:A
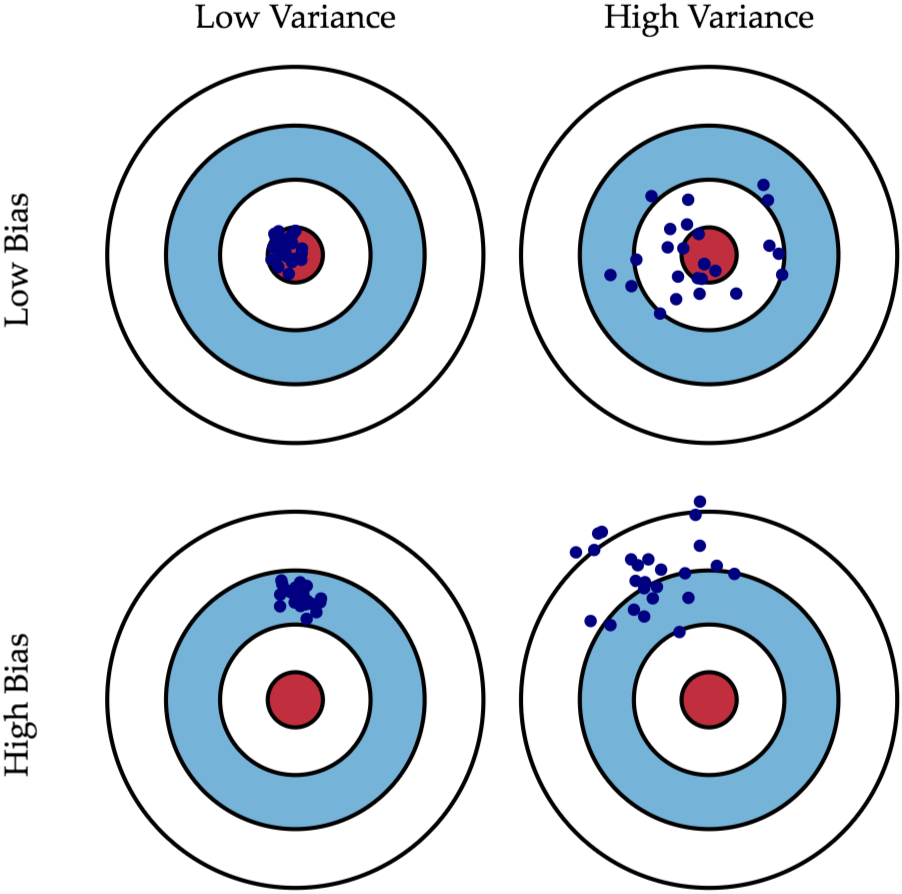
解析:Bias-Variance Tradeoff 是 ML 核心議題:偏差高 → 容易欠擬合;變異高 → 易過擬合。
18. 出題頻率/重要性:★★★
由講義出題:Yes(參考:01_AI基礎理論_講義.pdf 第50頁)
為何我們需要「驗證集 (Validation set)」?
答案:C
解析:在三階段切分中,Validation 協助調校模型參數,Test 保持獨立最終評估,避免洩露。
19. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
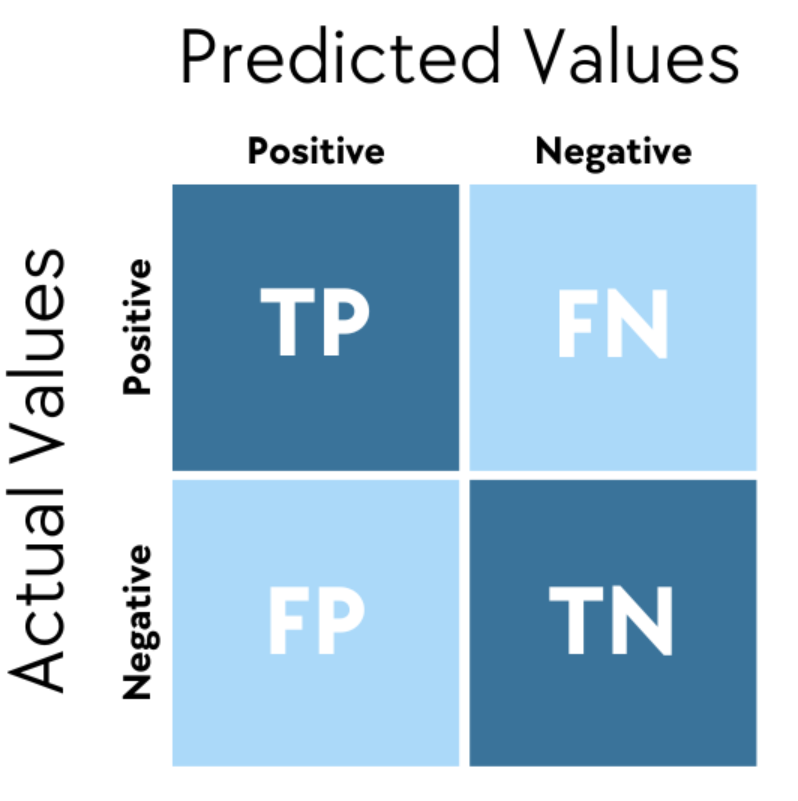
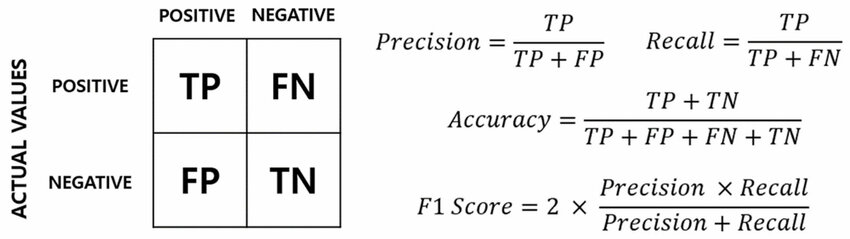
「混淆矩陣 (Confusion Matrix)」在分類任務中,能顯示什麼資訊?
答案:B
 "
"
解析:混淆矩陣是分類結果詳細對照表,可看出錯誤類型與準確預測的類別情況。
"
20. 出題頻率/重要性:★★
由大綱出題:Yes(參考:初級大綱.txt - L11301 機器學習基本原理)
下列對於「線性迴歸」的描述,何者較為正確?
答案:B
解析:線性迴歸適用於輸出為連續變數的場景,假設輸入-輸出呈線性關係。
21. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
在機器學習中,若資料量不夠但特徵維度很多,常有何問題?
答案:B

解析:高維度+少資料 → 難以估計參數;也因距離度量在高維下失效,致分類與回歸困難。
22. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第55頁)
PCA(主成分分析)主要用途是?
答案:C
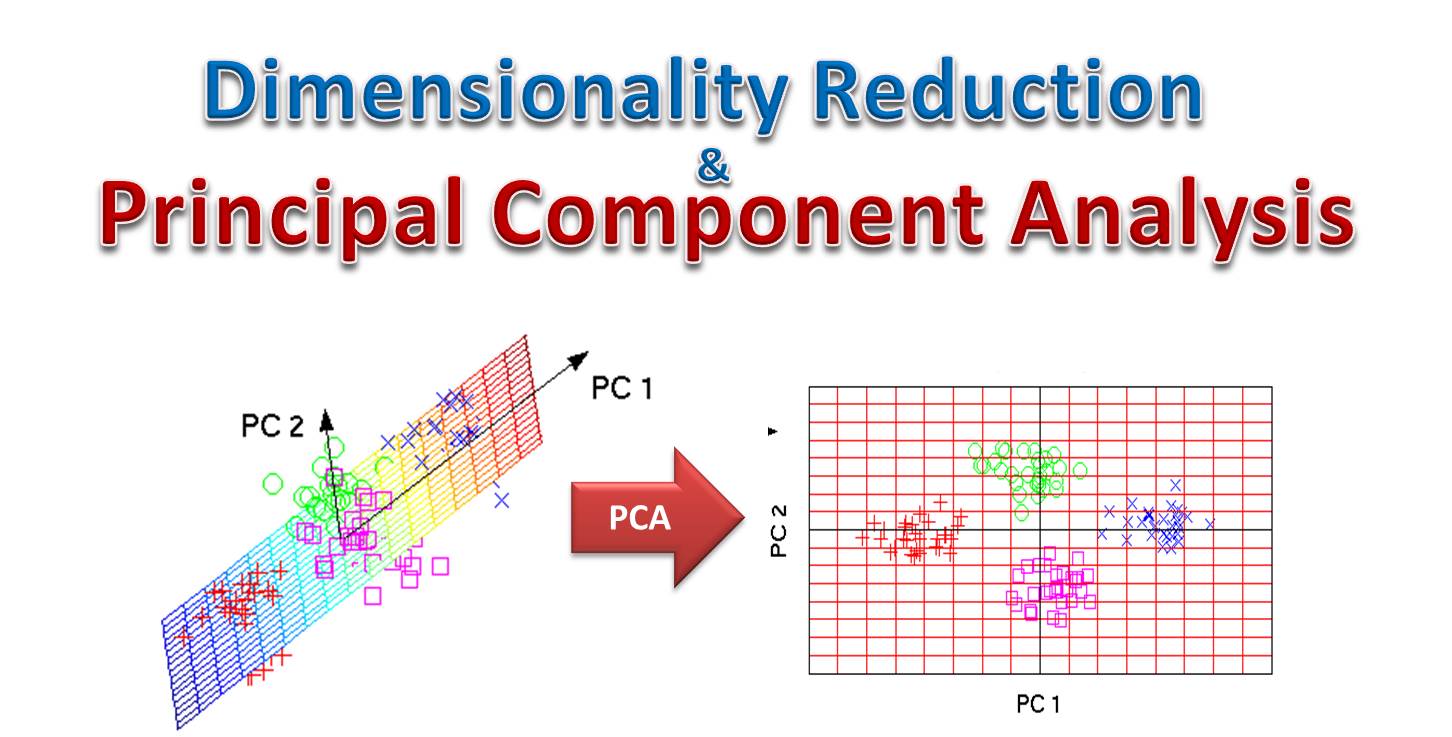
解析:PCA是一種降維方法,尋找能最大化資料方差的正交主成分,以壓縮維度。
23. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
在監督式學習中,分割資料時常見做法為多少比例?
答案:A
解析:常見切分包含 80%/20% 或 70%/30%;依資料量大小與需求可調整。
24. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
常見優化方法「梯度下降 (Gradient Descent)」的核心思路是什麼?
答案:A
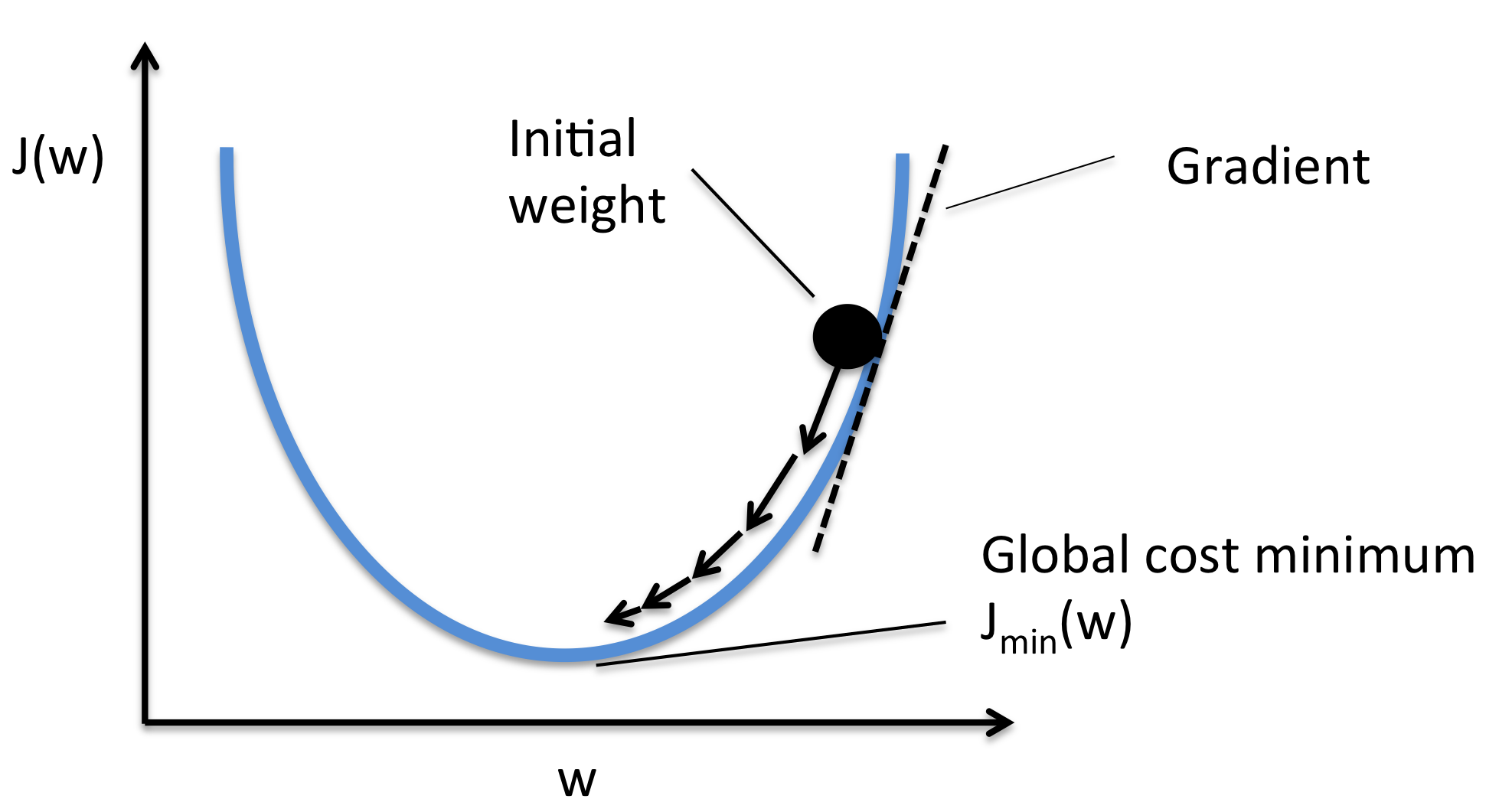
解析:梯度下降演算法是最常用的學習方式,透過更新參數以最小化損失。
25. 出題頻率/重要性:★★★
由大綱出題:Yes(參考:初級大綱.txt - L11301 機器學習基本原理)
下列哪一種是「深度學習 (Deep Learning)」與傳統機器學習的主要差異?
答案:A
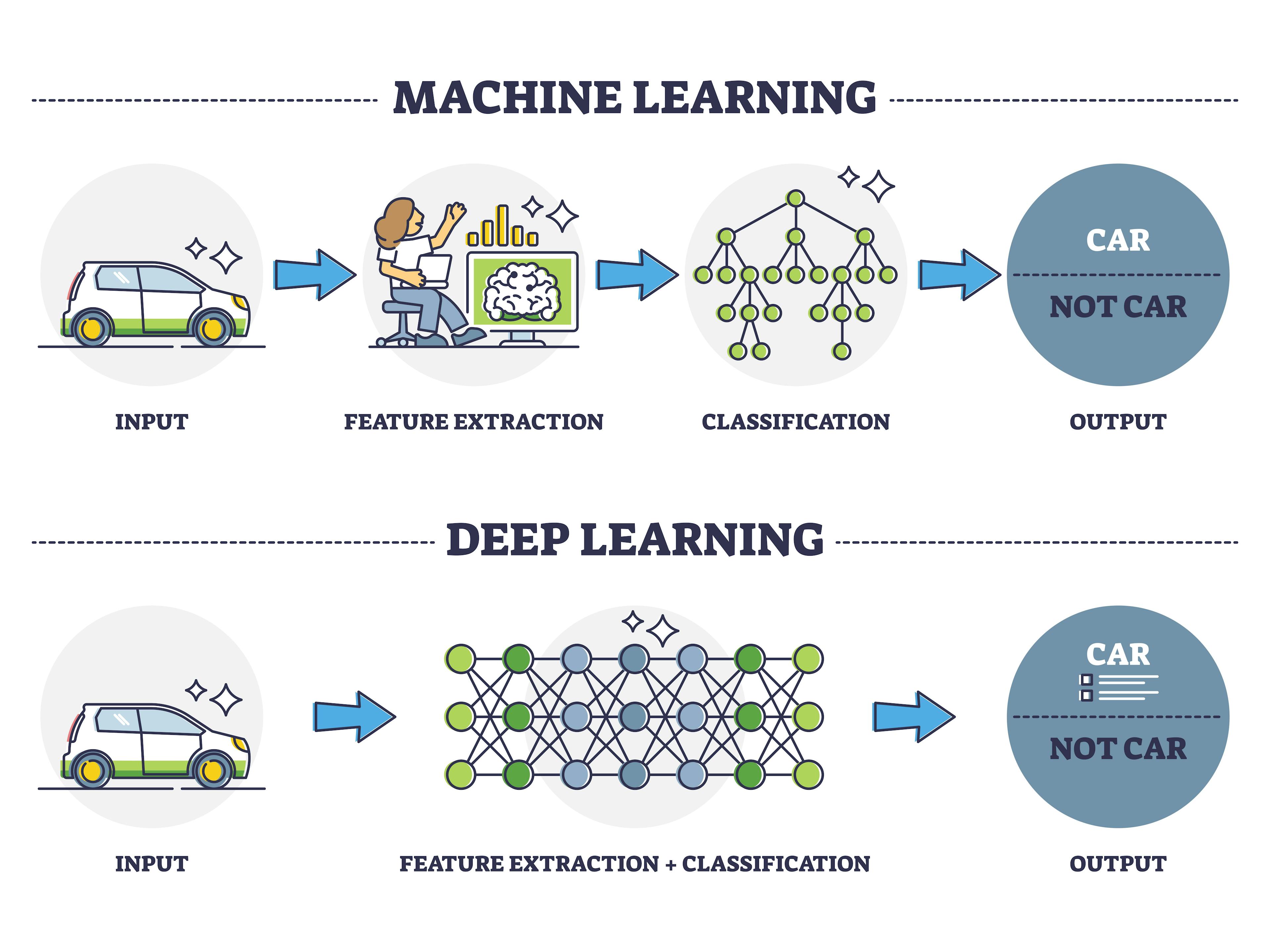 "
"
解析:深度學習網路具多層結構,自動抽取高階特徵,表現強大但依賴大量資料與算力。
"
26. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
對於「過擬合」問題,下列哪個敘述正確?
答案:B
解析:過擬合即模型只記住訓練樣本特徵,在新樣本的泛化不佳。
27. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
為何「Learning Rate」不能設得過大?
答案:A
"
解析:學習率太大會造成更新步伐過大,導致震盪或發散,無法到達最小值。
"
28. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第50頁)
「多元線性迴歸 (Multiple Linear Regression)」相較單一迴歸,多在哪裡?
答案:B
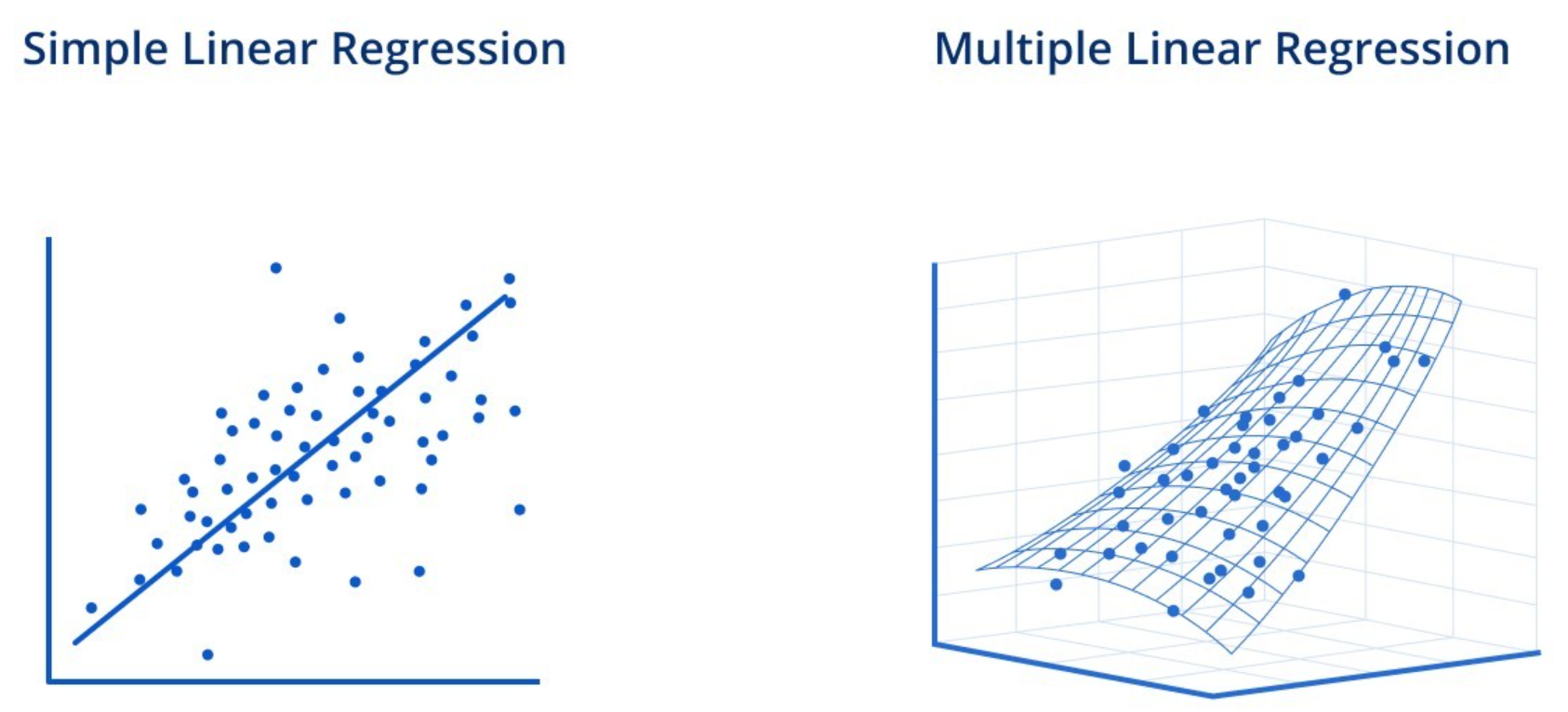
解析:多元線性迴歸係指 y = w1*x1 + w2*x2 + ... + b,特徵有多個。
29. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
在分類任務中,若非常重視對「少數正類」的召回率 (Recall),該怎麼做?
答案:A
解析:召回率要高,就要盡量把真正類都抓出來,可調低閾值,但可能犧牲精確率。
30. 出題頻率/重要性:★★
由大綱出題:Yes(參考:初級大綱.txt - L11301 機器學習基本原理)
下列哪一個不是機器學習常見的演算法家族?
答案:A
解析:形態學演算主要用於影像像素層面的膨脹/侵蝕,不算機器學習常見主流演算法。
31. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
「集成學習 (Ensemble)」如 Bagging、Boosting 的核心理念是什麼?
答案:A
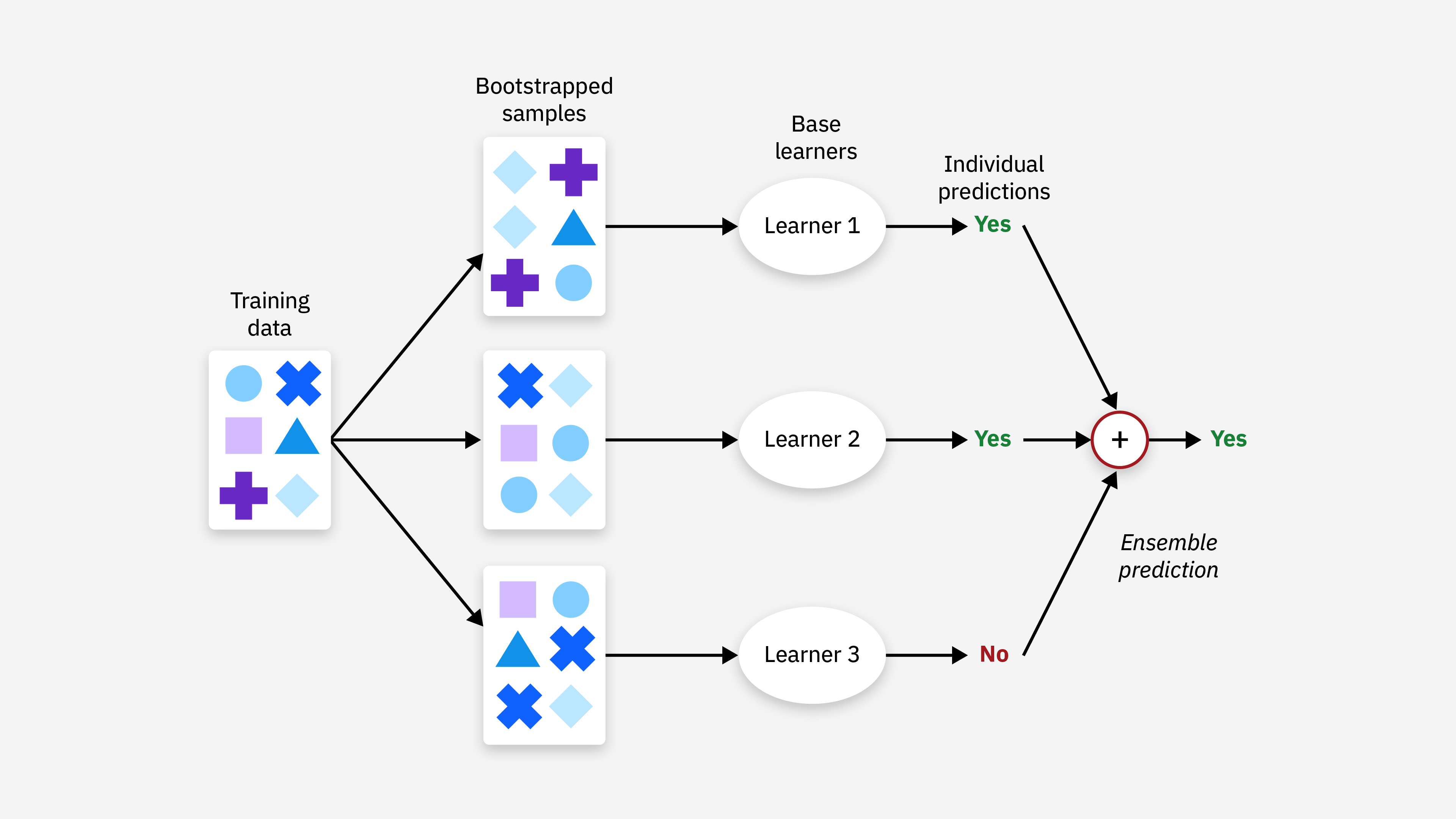
解析:集成方法如隨機森林(Bagging)或梯度提升(Boosting)常可有效提升預測表現。
32. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第58頁)
Boosting (如 XGBoost、LightGBM) 與 Bagging (如 Random Forest) 的差異在?
答案:A
解析:Bagging是並行訓練後投票;Boosting是序列化,後面針對前面錯誤做加強。
33. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
為何在高維空間下,KNN 分類可能效果較差?
答案:B
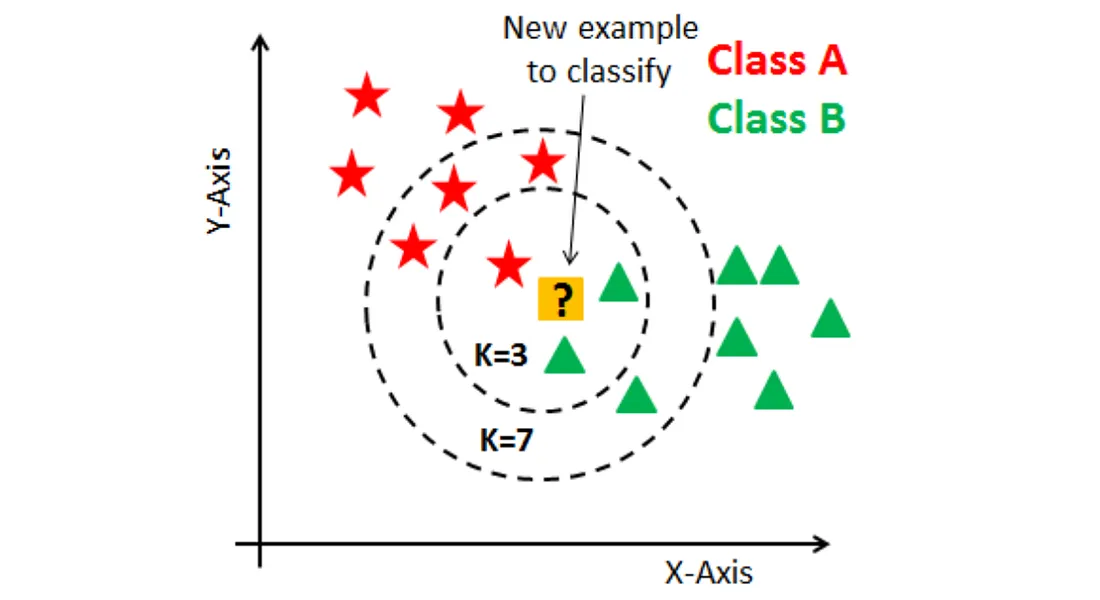
解析:在高維空間,所有點都「差不多遠」,KNN對距離的依賴嚴重削弱效果。
34. 出題頻率/重要性:★★
由大綱出題:Yes(參考:初級大綱.txt - L11301 機器學習基本原理)
機器學習中,為何要做「資料正規化 (Normalization)」或「標準化 (Standardization)」?
答案:A
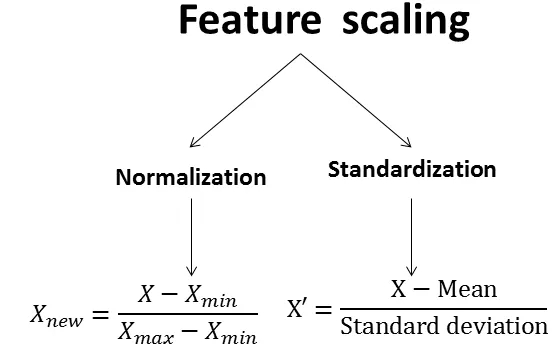
解析:資料縮放可加速收斂、提高數值穩定,避免大值特徵嚴重影響損失函式。
35. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第63頁)
L1 正則化 (Lasso) 與 L2 正則化 (Ridge) 的主要差異?
答案:A
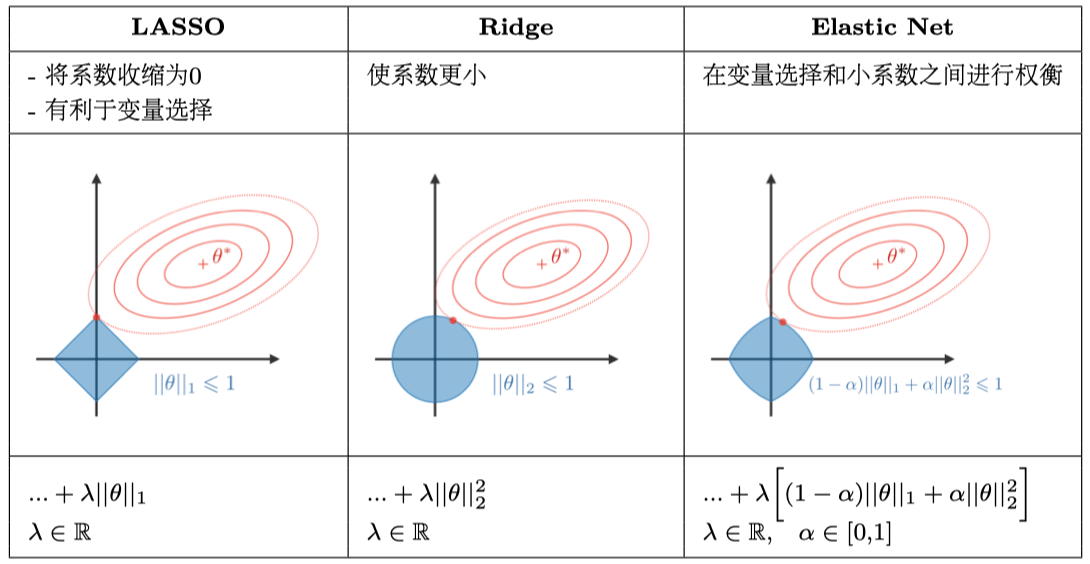
解析:L1(Lasso)可做特徵選擇;L2(Ridge)則抑制權重過大但不會直接變0。
36. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
在邏輯迴歸中,激活函式常用哪種?
答案:C

解析:邏輯迴歸透過 sigmoid 將線性組合輸出映射到 0~1 的機率空間。
37. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
SVM (支持向量機) 中的「核函式 (Kernel)」作用為何?
答案:A
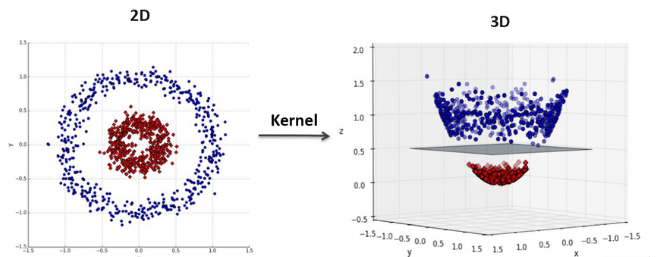
解析:核函式可在不顯式映射至高維的情況下計算內積,SVM因此可處理非線性分界。
38. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第72頁)
ROC 曲線指的是?
答案:A
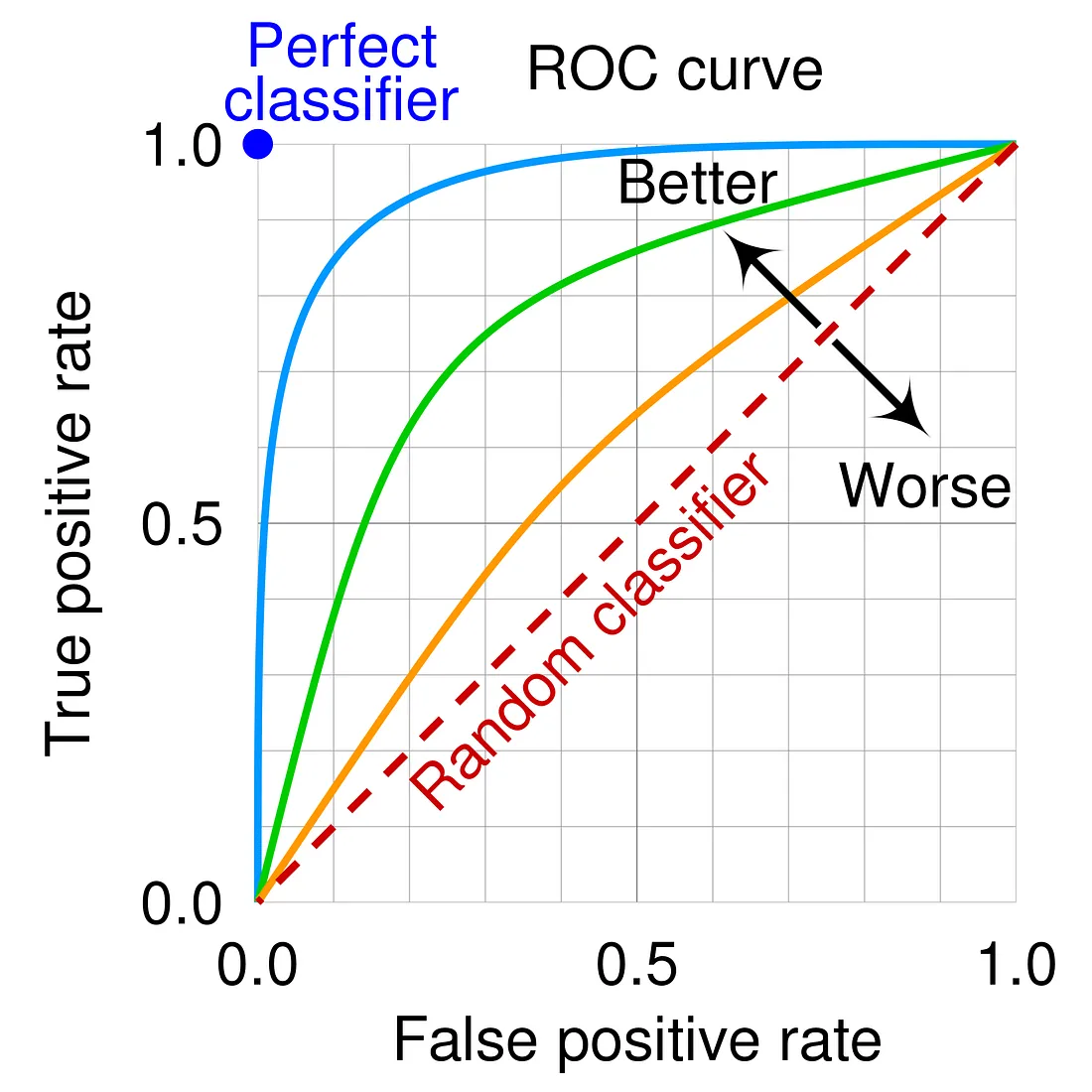
解析:ROC(Receiver Operating Characteristic) 曲線反映分類器在各閾值下的真陽性率與假陽性率。
39. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
AUC (Area Under the Curve) 通常指的就是 ROC 曲線下的面積,意義為何?
答案:A
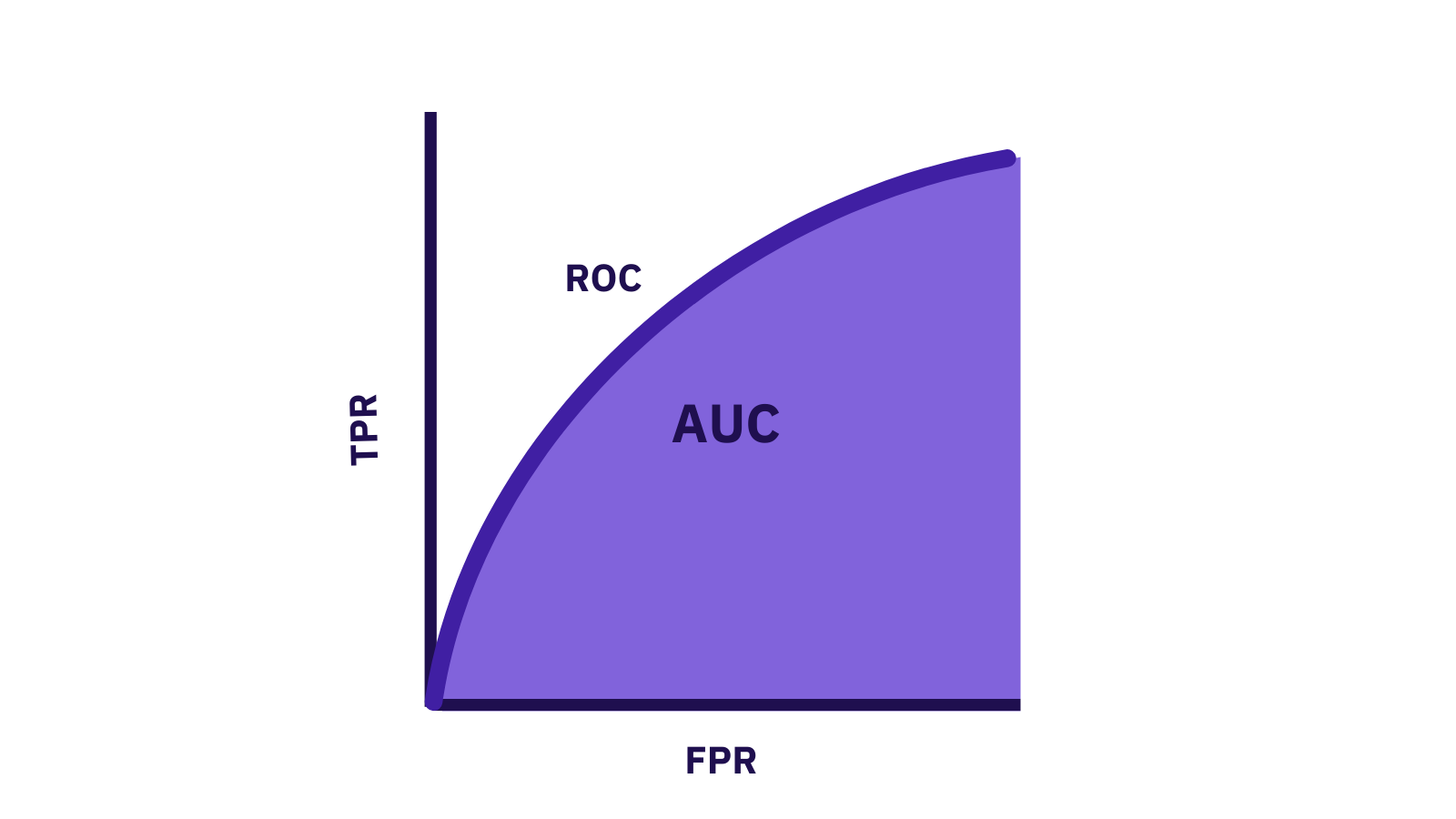
解析:AUC越高,代表對正負類別區分能力越強;0.5表示無區分能力。
40. 出題頻率/重要性:★★
由大綱出題:Yes(參考:初級大綱.txt - L11301 機器學習基本原理)
「學習曲線 (Learning Curve)」在模型訓練中可觀察什麼?
答案:A
解析:學習曲線可看隨資料量增多時,模型的訓練誤差與驗證誤差如何變化,以判斷是否需更多資料或更複雜模型。
41. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
KNN 分類中的 K 值若過大,可能出現什麼情況?
答案:B
解析:K太大會忽略局部區域特性,分類決策受遠方多數樣本干擾。
42. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第68頁)
「早停 (Early Stopping)」的主要目的為何?
答案:A
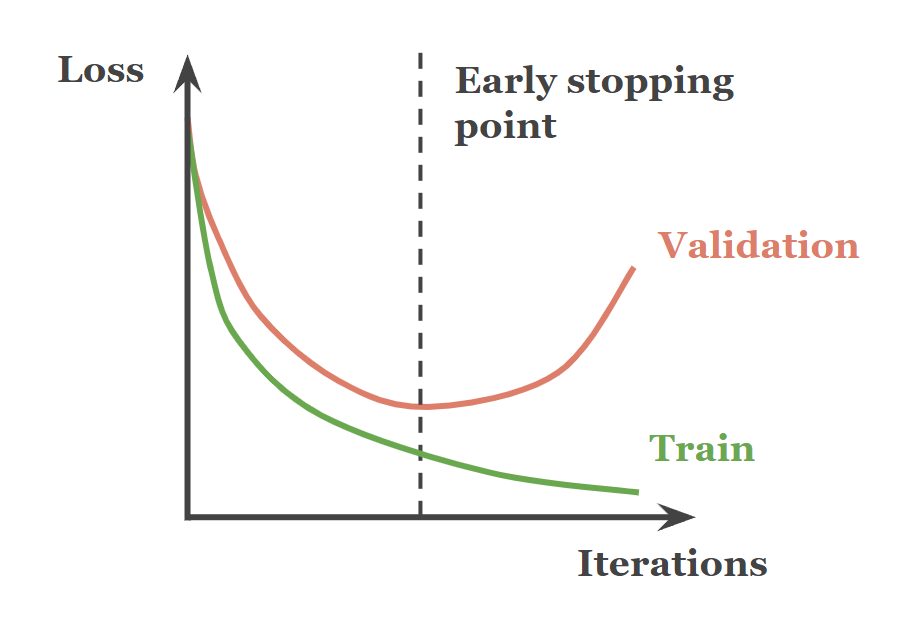 "
"
解析:Early Stopping 會根據驗證集誤差是否上升來提前終止訓練,防止模型繼續記住訓練雜訊。
"
43. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
「偏差 (Bias)」過大時,模型較可能是哪種狀況?
答案:A
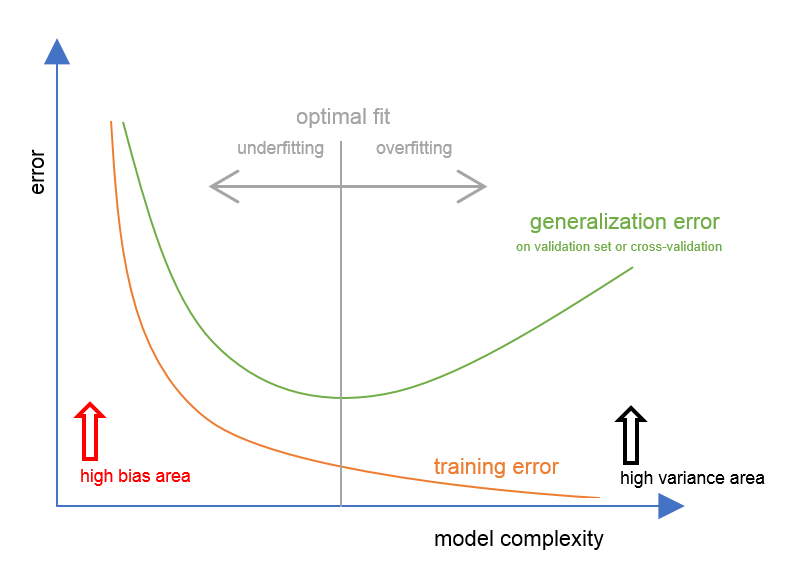
解析:高偏差表示模型過於簡單或錯誤假設,導致欠擬合現象。
44. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
為何選用「F1-score」作為分類指標,而不僅用 Accuracy?
答案:B
解析:F1 = 2PR/(P+R),能同時考量精確率與召回率,特別適用不平衡資料。
45. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第72頁)
若在二元分類中,非常重視「不漏抓正類」,應優先提升哪個指標?
答案:B
解析:若要確保正類都抓到(不漏報),就是提高召回率=TP/(TP+FN),盡量降低FN。
46. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
當 Accuracy 很高,但 F1-score 很低,可能表示什麼?
答案:A
解析:不平衡資料下,光看Accuracy易誤導,模型可能無視少數類,導致F1分數低。
47. 出題頻率/重要性:★★
由大綱出題:Yes(參考:初級大綱.txt - L11301 機器學習基本原理)
機器學習在實務上常需持續迭代更新模型,原因是?
答案:A
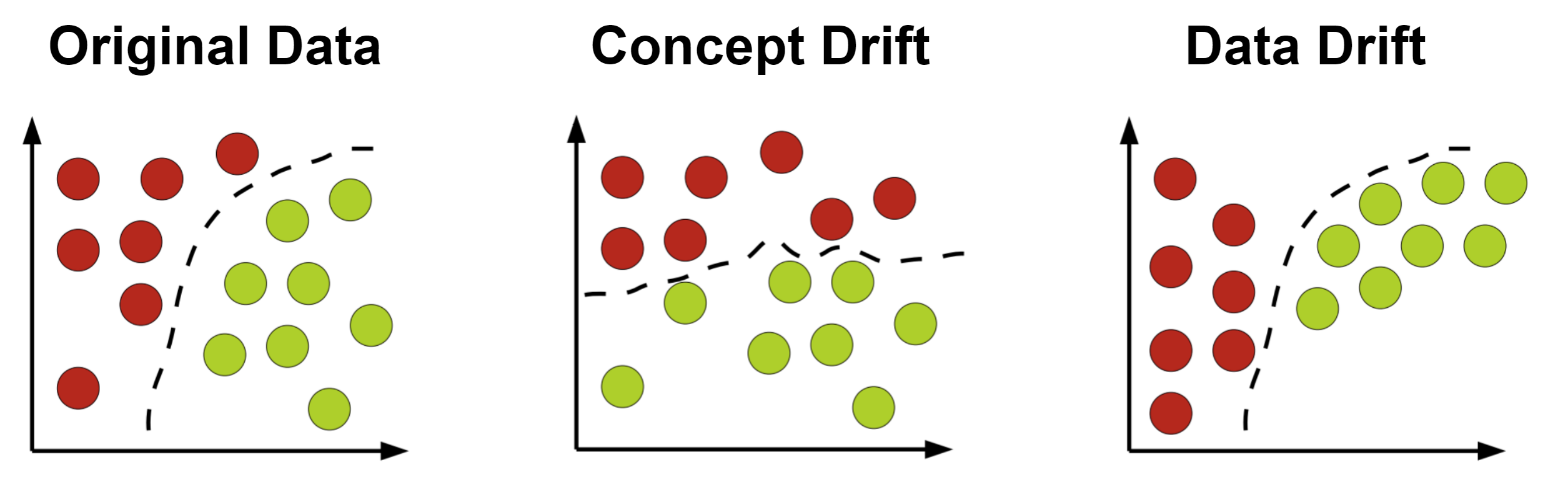
解析:實際環境中資料與行為模式會變化,故需定期重新蒐集與訓練模型。
48. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第80頁)
Gradient Boosting 的原理為何?
答案:A
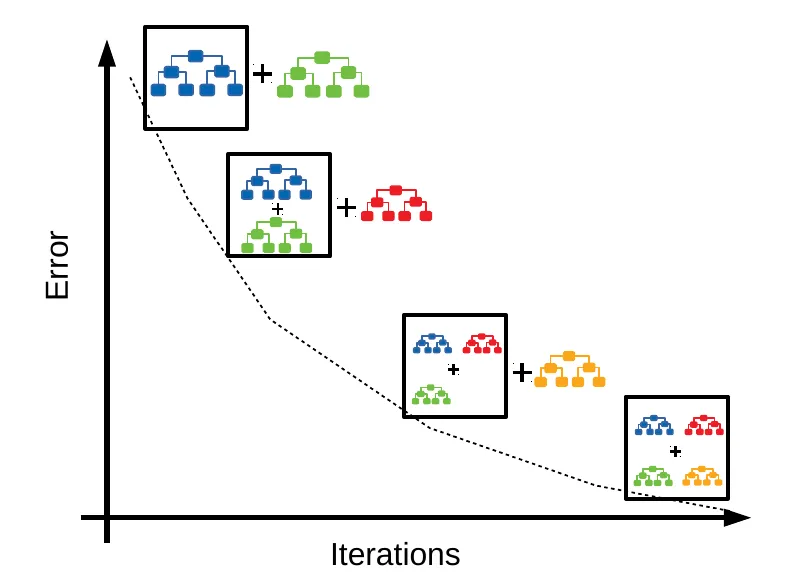
解析:Boosting將每次學習的誤差當作新標籤,不斷累加調整模型,最終形成強分類器。
49. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
在非監督式學習中,若要估計分群數 K,常用哪種方法?
答案:B
解析:Elbow method 觀察 SSE對K的走勢,輪廓係數衡量分群品質等,用以選擇合適K。
50. 出題頻率/重要性:★★★
由講義出題:Yes(參考:01_AI基礎理論_講義.pdf 第70頁)
綜觀「L11301 機器學習基本原理」,下列哪句最能代表其核心精神?
答案:C
解析:機器學習本質在於「從資料中學習」並「應用於新情況」,透過演算法與模型評估持續優化。
51. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第85頁)
欲評估模型在不同樣本量下的表現趨勢,我們可使用哪種曲線?
答案:A
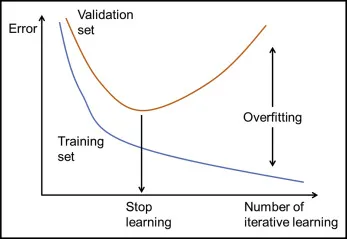
解析:Learning Curve 顯示隨資料量變化時,訓練/驗證誤差的走勢,幫助判斷是否需更多資料。
52. 出題頻率/重要性:★★
由講義出題:Yes(參考:01_AI基礎理論_講義.pdf 第52頁)
選用「梯度提升樹 (Gradient Boosted Trees)」模型時,通常可得到什麼好處?
答案:B
解析:像 XGBoost、LightGBM、CatBoost 等屬於梯度提升樹方法,常在各種競賽中表現良好。
53. 出題頻率/重要性:★
由大綱出題:Yes(參考:初級大綱.txt - L11301 機器學習基本原理)
為了加速迴歸或分類模型的收斂,我們常在輸入特徵上做哪件事?
答案:B
解析:對特徵做縮放(如 Z-score)能讓梯度計算更穩定,避免尺度差異造成學習困難。
54. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
「多項式迴歸 (Polynomial Regression)」如何對非線性關係做擬合?
答案:A
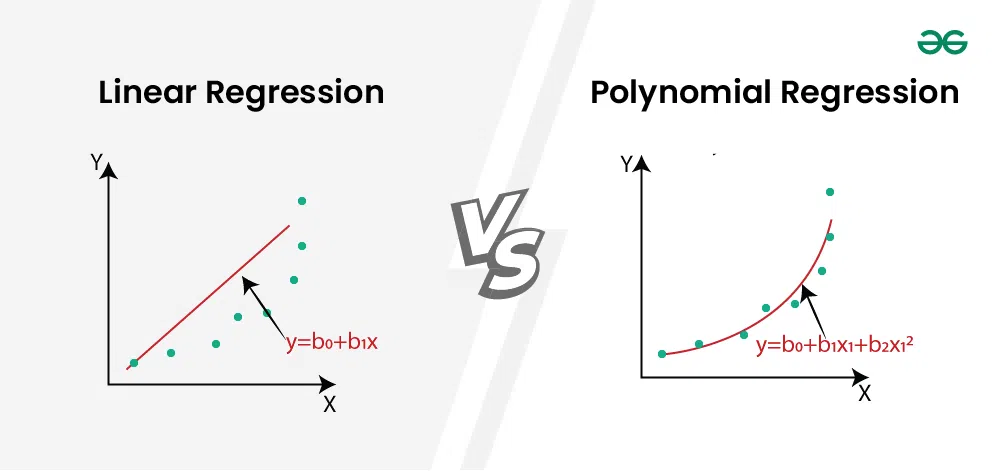
解析:多項式迴歸透過手動擴增特徵(多次方),讓線性模型能擬合非線性關係。
55. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第95頁)
「Early Stopping」在 Boosting 模型中也常被使用,其原因?
答案:B
"
解析:像 XGBoost 也可透過 early_stopping_rounds 參數根據驗證集分數停止迭代。
"
56. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
在自動化ML流程中,「AutoML」可以做什麼?
答案:A
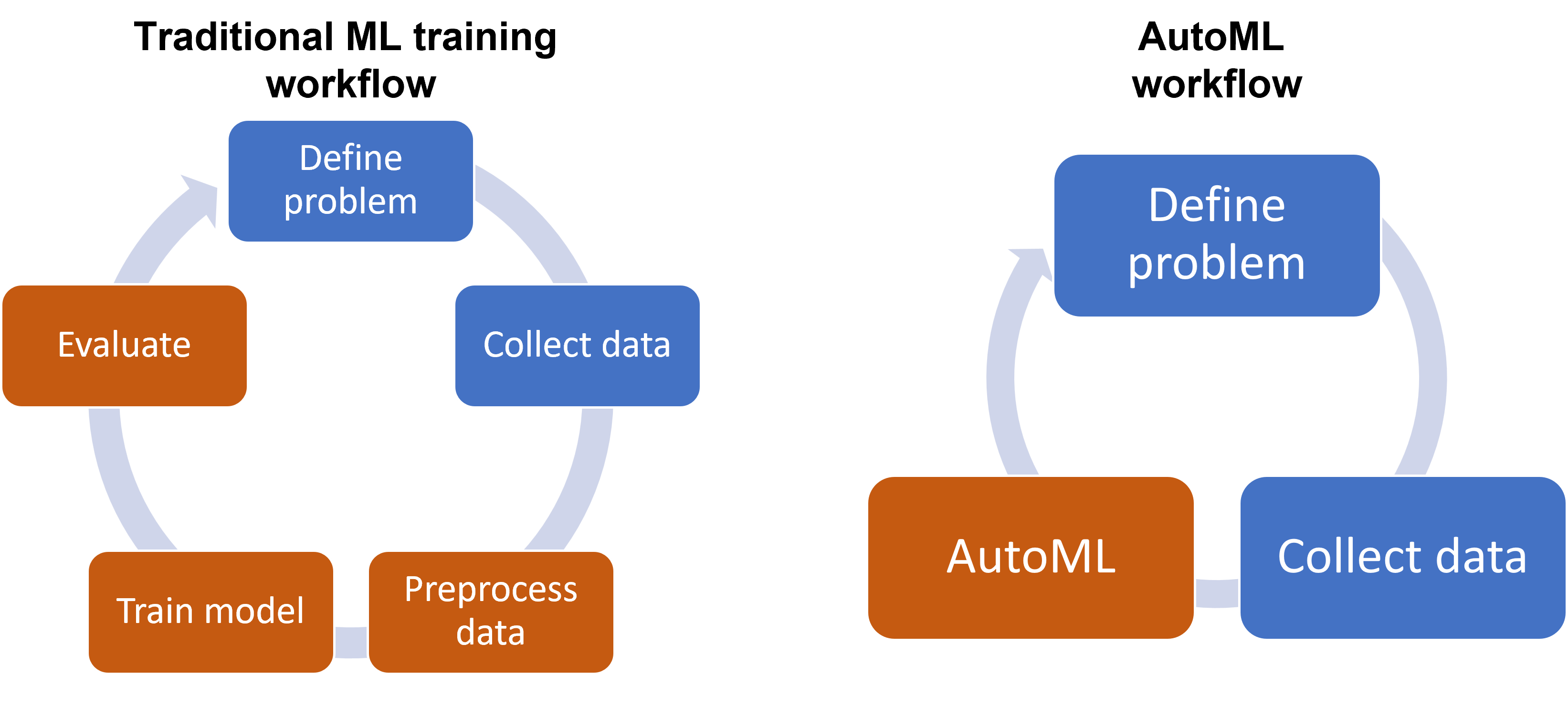
解析:AutoML 工具可嘗試多種模型與管線組合,尋找最好表現,減輕人力。
57. 出題頻率/重要性:★★
由大綱出題:Yes(參考:初級大綱.txt - L11301 機器學習基本原理)
「正則化 (Regularization)」的主要目的為?
答案:A
解析:如 L1、L2、Dropout(深度學習)等方法,目的都在減少模型複雜度、增進泛化。
58. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第102頁)
在樹模型中,如何判斷哪個特徵最先分裂比較好?
答案:A
解析:決策樹常用資訊增益(ID3/C4.5)或基尼指數(CART)選出最能區分資料的特徵。
59. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
在 Logistic Regression 中,Loss Function 通常為?
答案:B
解析:Logistic Regression 透過對數似然估計,可視為 Cross Entropy 損失形式。
60. 出題頻率/重要性:★★
由大綱出題:Yes(初級大綱.txt - L11301 機器學習基本原理)
「Loss Function」在機器學習訓練中扮演什麼角色?
答案:B
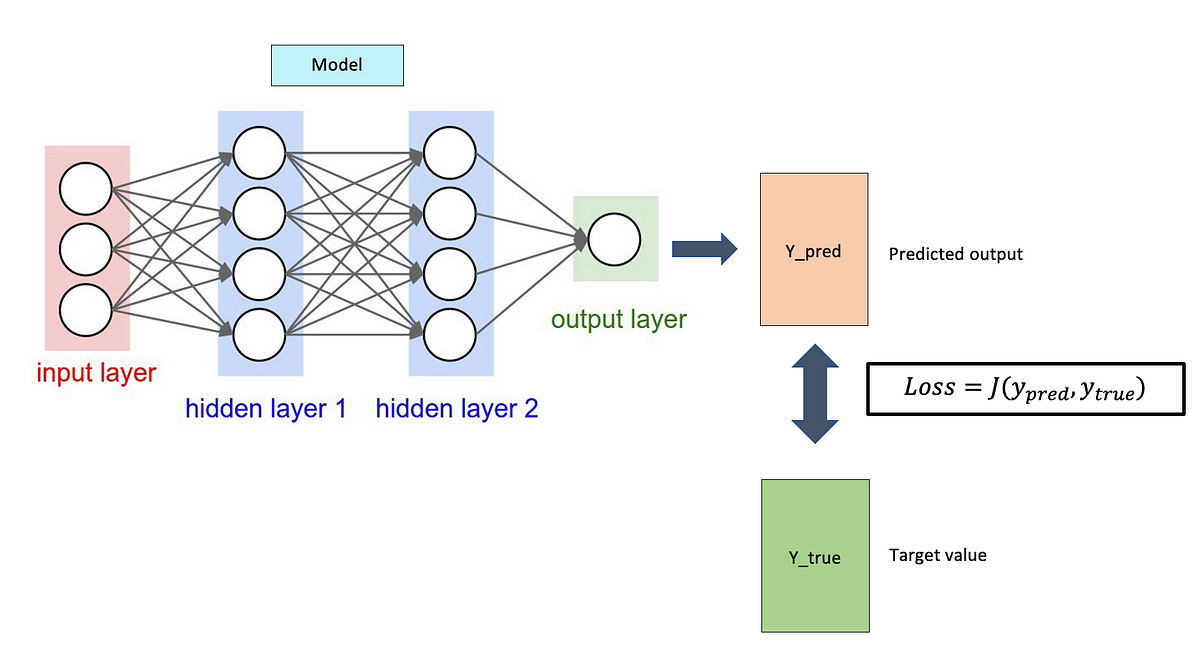
解析:Loss (損失) 用於量化預測的好壞,梯度下降等方法依此指標更新模型參數。
61. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
「One-Hot Encoding」主要用於?
答案:C
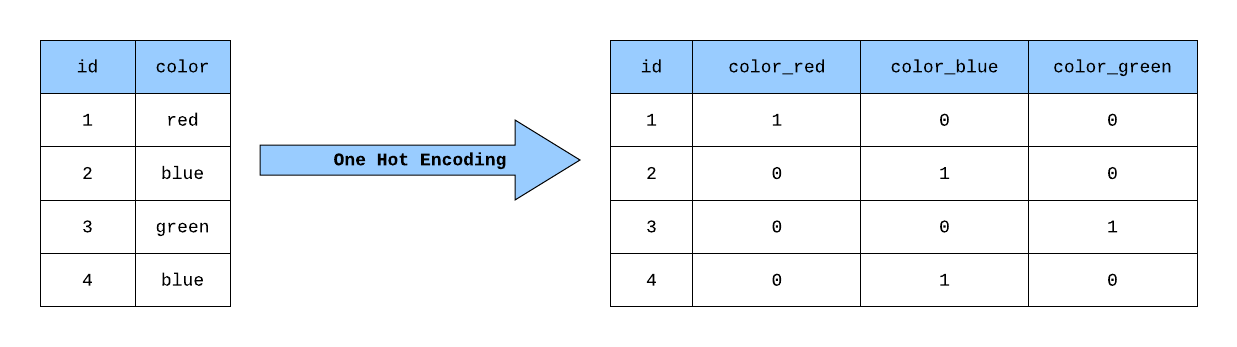
解析:One-Hot Encoding 是對分類特徵做離散化編碼,以便於線性或樹模型處理。
62. 出題頻率/重要性:★★
由講義出題:Yes(參考:01_AI基礎理論_講義.pdf 第55頁)
當我們對資料做降維 (如 PCA) 時,可能的優勢為?
答案:A
解析:PCA等方法壓縮維度,去除冗餘特徵,能提取關鍵特徵並減少運算量。
63. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第110頁)
隨機森林有一項「Out-of-Bag (OOB)」的概念,其用途為?
答案:A
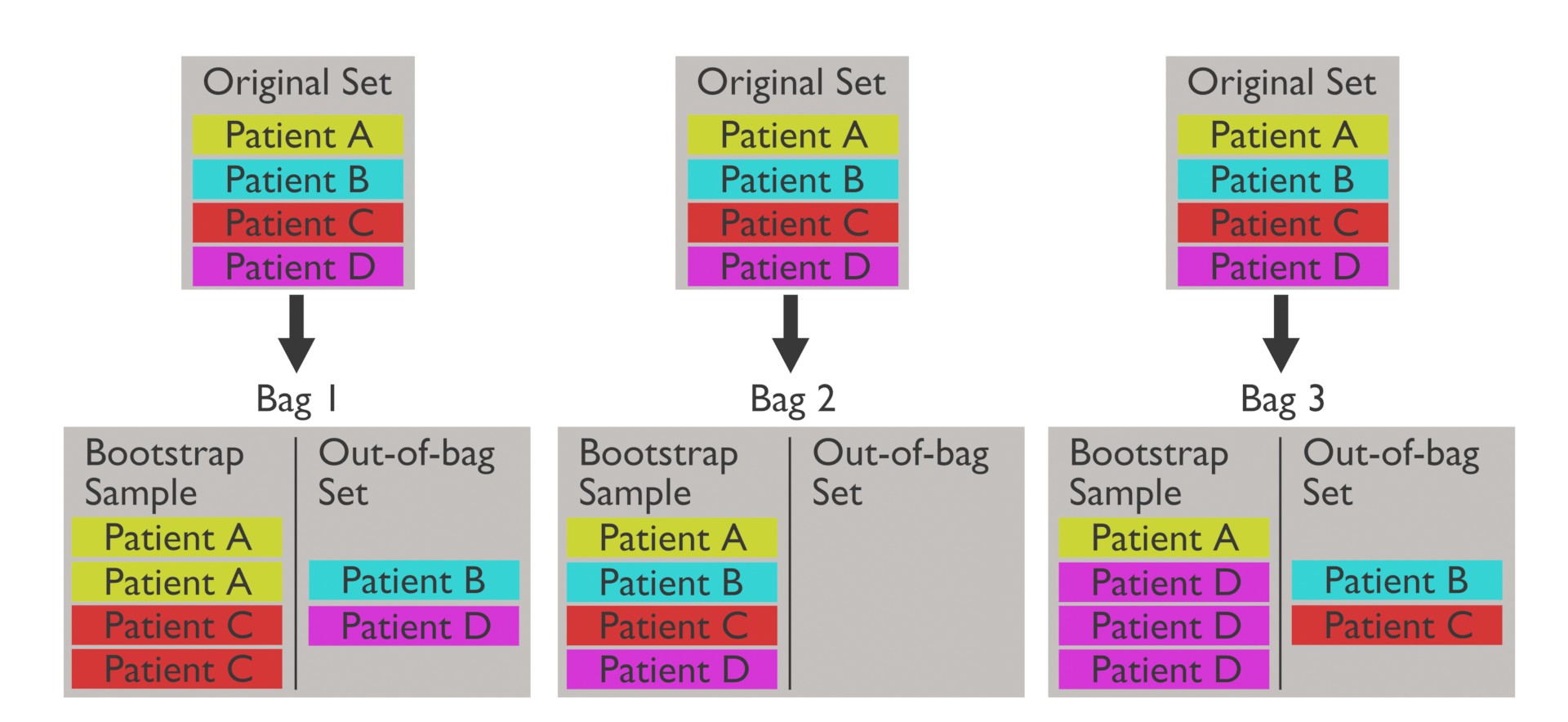
解析:每棵樹訓練時是有放回抽樣,故有部分樣本沒被抽中,可用來做該樹的驗證,稱OOB測試。
64. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
在SVM的分類決策裡,「支持向量 (Support Vectors)」指的是?
答案:B
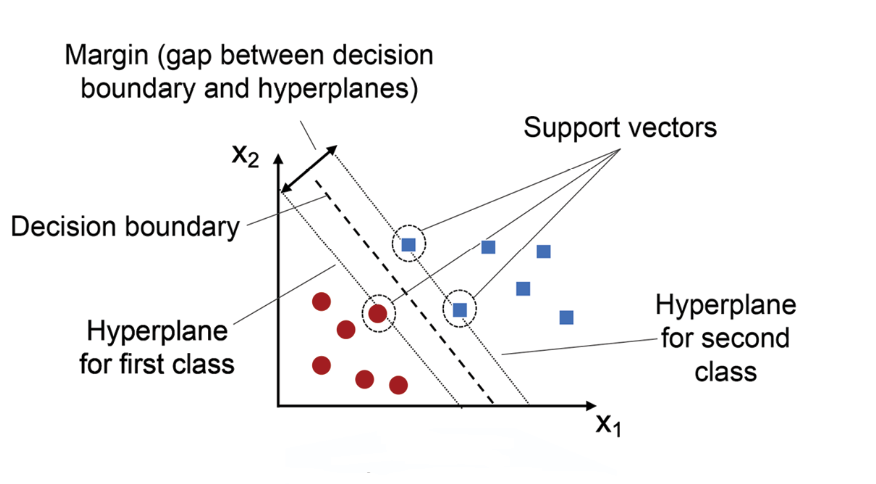
解析:SVM只需靠部分臨界樣本(支持向量)定義決策邊界,其餘距邊界遠的樣本不影響結果。
65. 出題頻率/重要性:★★
由大綱出題:Yes(初級大綱.txt - L11301 機器學習基本原理)
我們通常用「學習率衰減 (Learning Rate Decay)」來做什麼?
答案:A
解析:初期可快速下降,後期需更小步伐搜尋極小值,防止震盪。
66. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第114頁)
XGBoost 之所以常被用於競賽的原因?
答案:A
解析:XGBoost 是強化版梯度提升樹,支援並行、正則化、缺失值處理等特性,實務成效顯著。
67. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
機器學習中常用「批次大小 (Batch Size)」為何?
答案:A
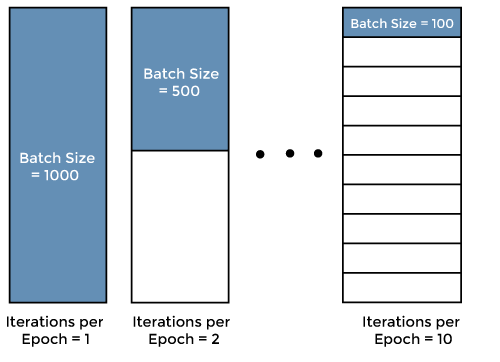
解析:在mini-batch梯度下降中,一次更新會基於該批次資料的平均梯度。
68. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
為何在做 K-Fold Cross Validation 時,某些情況下會用 Stratified K-Fold?
答案:A
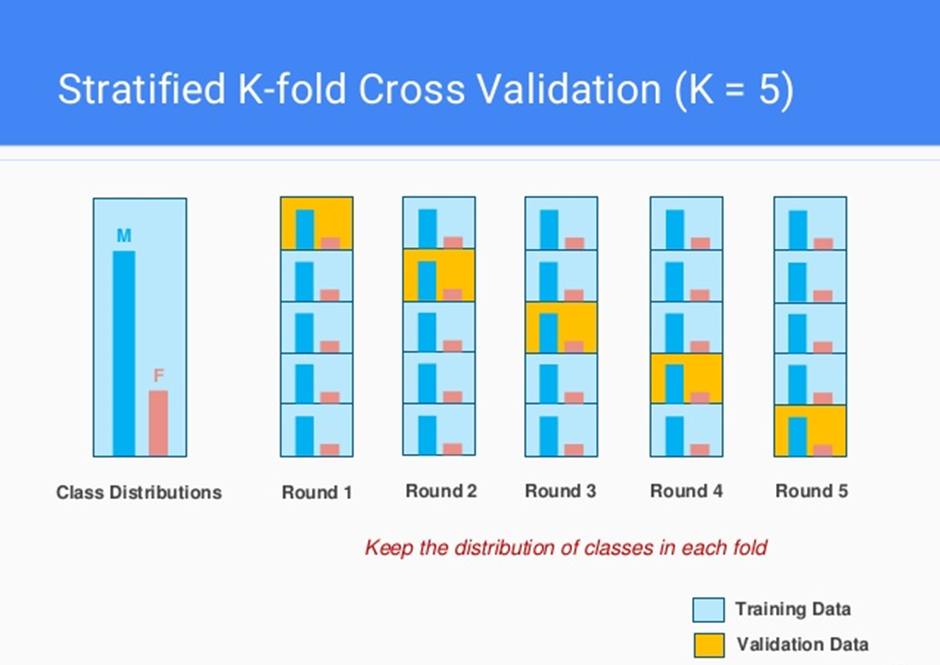
解析:Stratified會分層抽樣,維持類別比例一致,使訓練/驗證集更具代表性。
69. 出題頻率/重要性:★★★
由大綱出題:Yes(初級大綱.txt - L11301 機器學習基本原理)
若模型在訓練集與測試集誤差都很高,表示什麼狀況?
答案:A
解析:同時在訓練/測試都表現差 → 欠擬合 → 模型太簡單或特徵不足。
70. 出題頻率/重要性:★
由講義出題:Yes(參考:01_AI基礎理論_講義.pdf 第65頁)
「資料增強 (Data Augmentation)」在某些情境下如何幫助減少過擬合?
答案:A
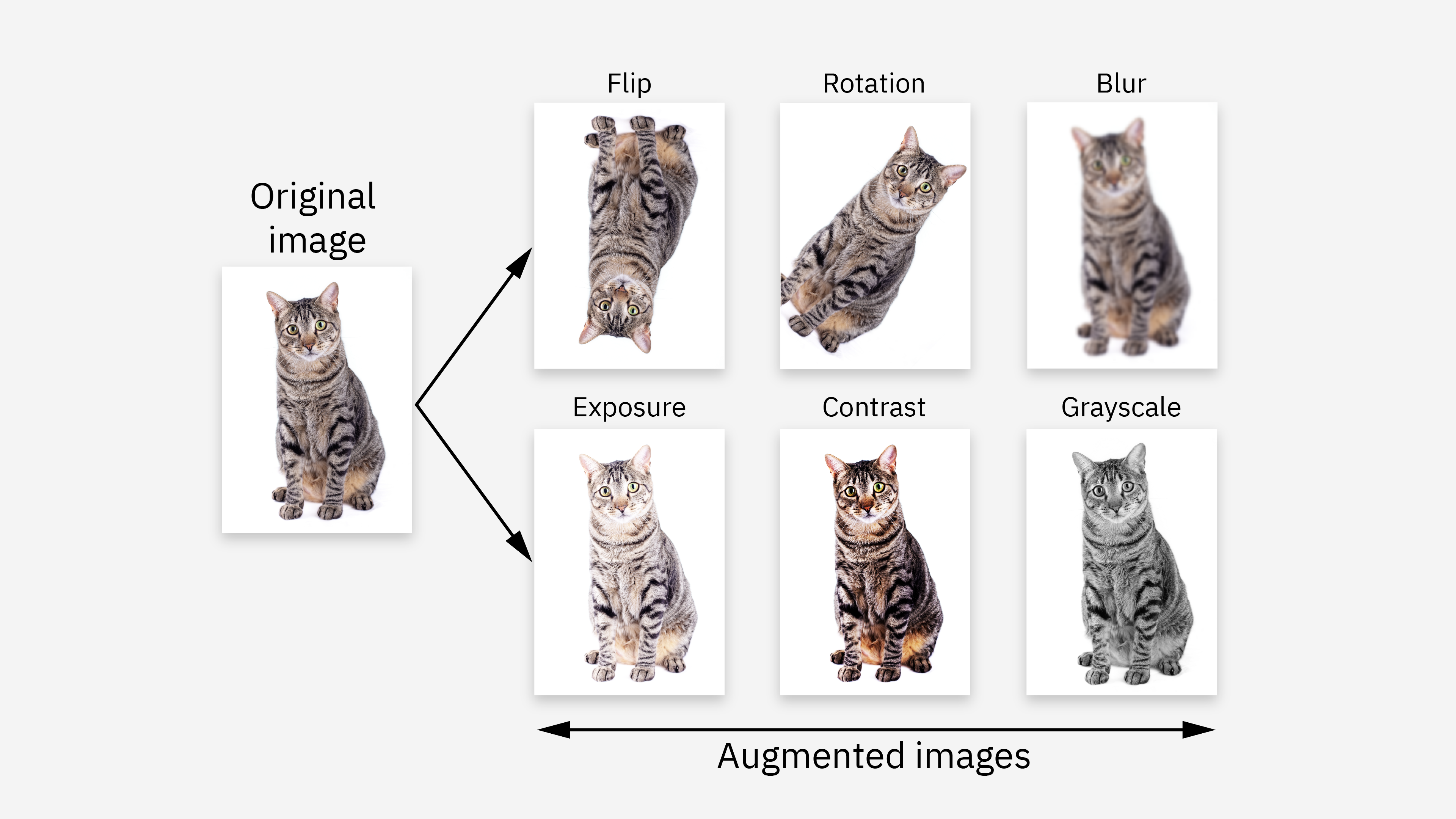
解析:在影像/文字等場合,資料增強可有效增加樣本多樣性,降低記住訓練集而無法泛化的風險。
71. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
在多分類問題(>2類),常用的評估方式?
答案:A
解析:多分類中 Accuracy、平均F1等常使用;也可看混淆矩陣觀察各類型誤判情況。
72. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第120頁)
在大型資料集下,為什麼 Mini-Batch Gradient Descent 通常優於全量 Batch Gradient Descent?
答案:A
解析:Mini-Batch 兼具隨機性與效率,可在不讀取整批資料的情況下更新參數。
73. 出題頻率/重要性:★
由大綱出題:Yes(初級大綱.txt - L11301 機器學習基本原理)
常見應用於「維度極高」資料,但標籤數據極少時,哪種學習能發揮作用?
答案:B
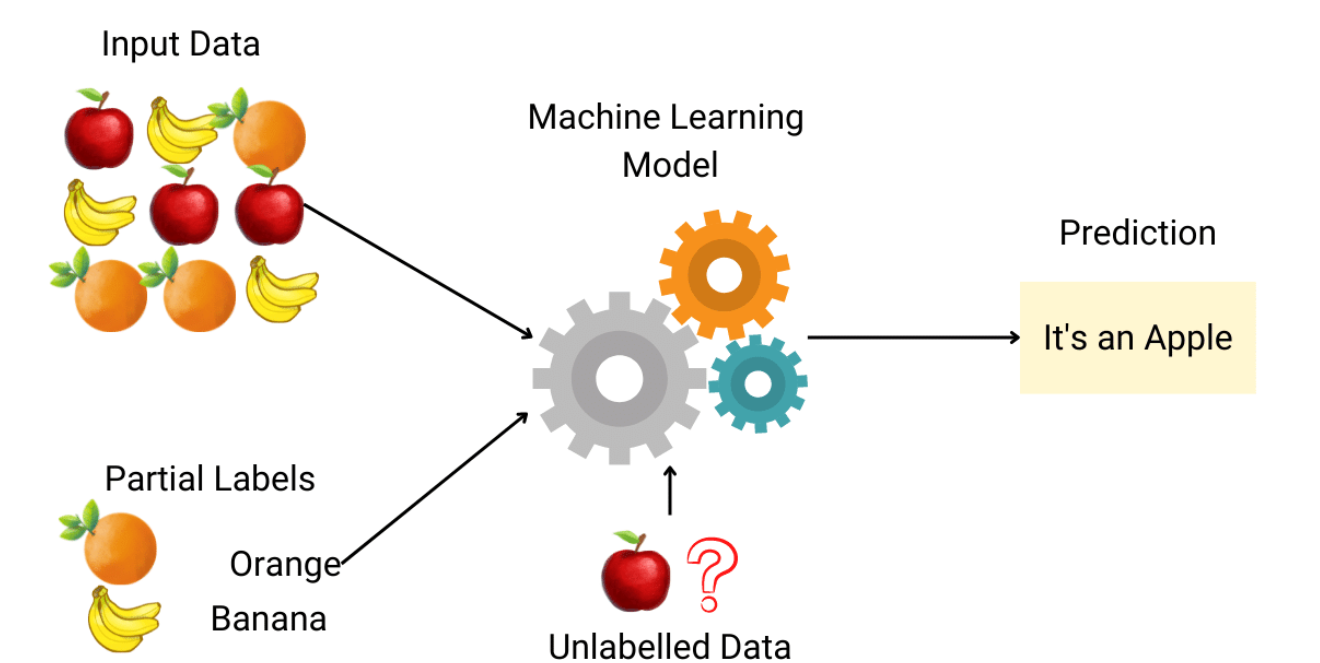
解析:半監督可用少量標籤+大量無標籤資料,較適合標註成本高但資料豐富情況。
74. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
「Zero-shot Learning」在機器學習中是指?
答案:B
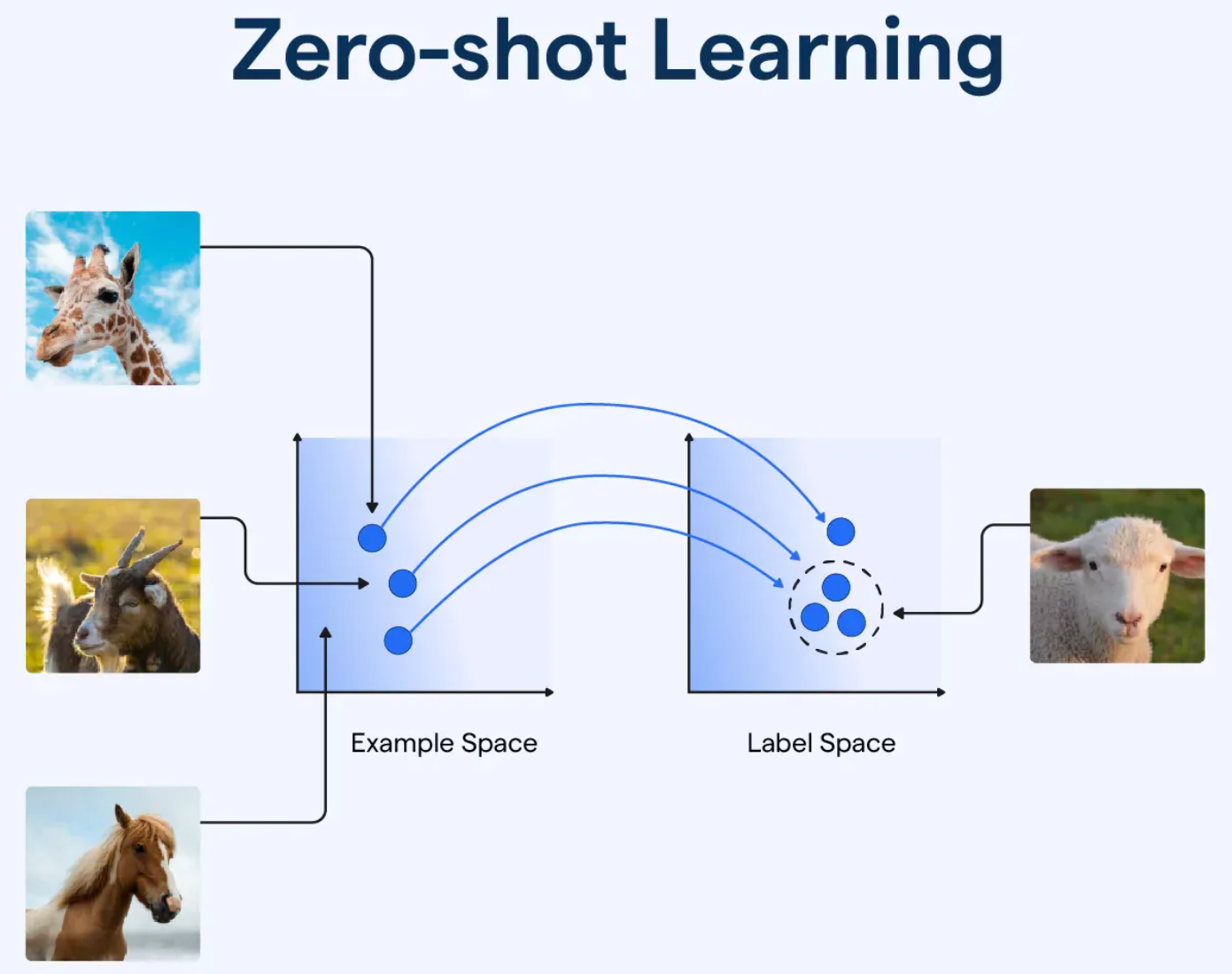
解析:Zero-shot指事先無該類別樣本,但模型可依先前語意或特徵知識辨識新的類別。
75. 出題頻率/重要性:★★★
由講義出題:Yes(參考:01_AI基礎理論_講義.pdf 第72頁)
在實務應用中,為何常用集成方法(如RandomForest、XGBoost) 而非單一樹或單一迴歸?
答案:A
解析:多模型投票/加權能降低方差與偏差,往往在Kaggle競賽等實踐中效果出色。
76. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
「偏差-變異分解 (Bias-Variance Decomposition)」可解釋誤差由哪些部分構成?
答案:A
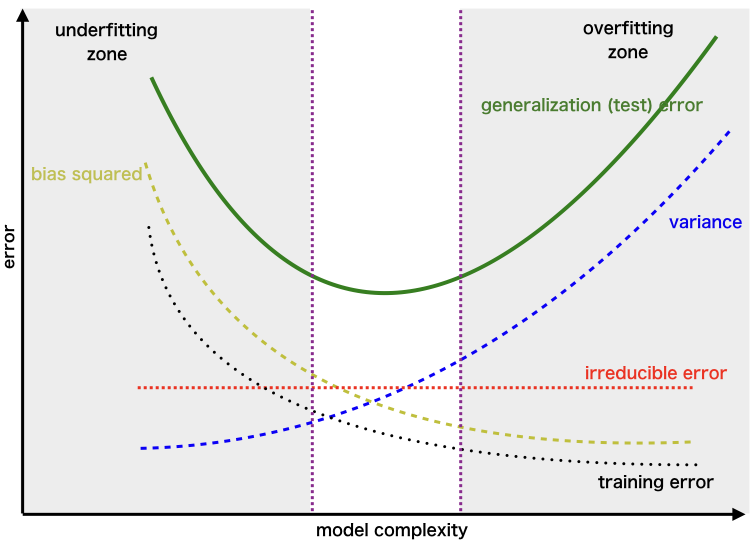
解析:模型預測誤差可分為: 偏差 (模型簡化誤差) + 變異(對不同訓練集敏感度) + 固有雜訊。
77. 出題頻率/重要性:★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第130頁)
「核 (Kernel) SVM」中,RBF核 (Gaussian Kernel) 的作用為何?
答案:A
解析:RBF核能將原始空間映射到高維(甚至無限),在該空間中以超平面做線性分割。
78. 出題頻率/重要性:★★★
由講義出題:Yes(參考:01_AI基礎理論_講義.pdf 第75頁)
「貝氏分類器 (Naive Bayes)」中,為何稱作"Naive"?
答案:A
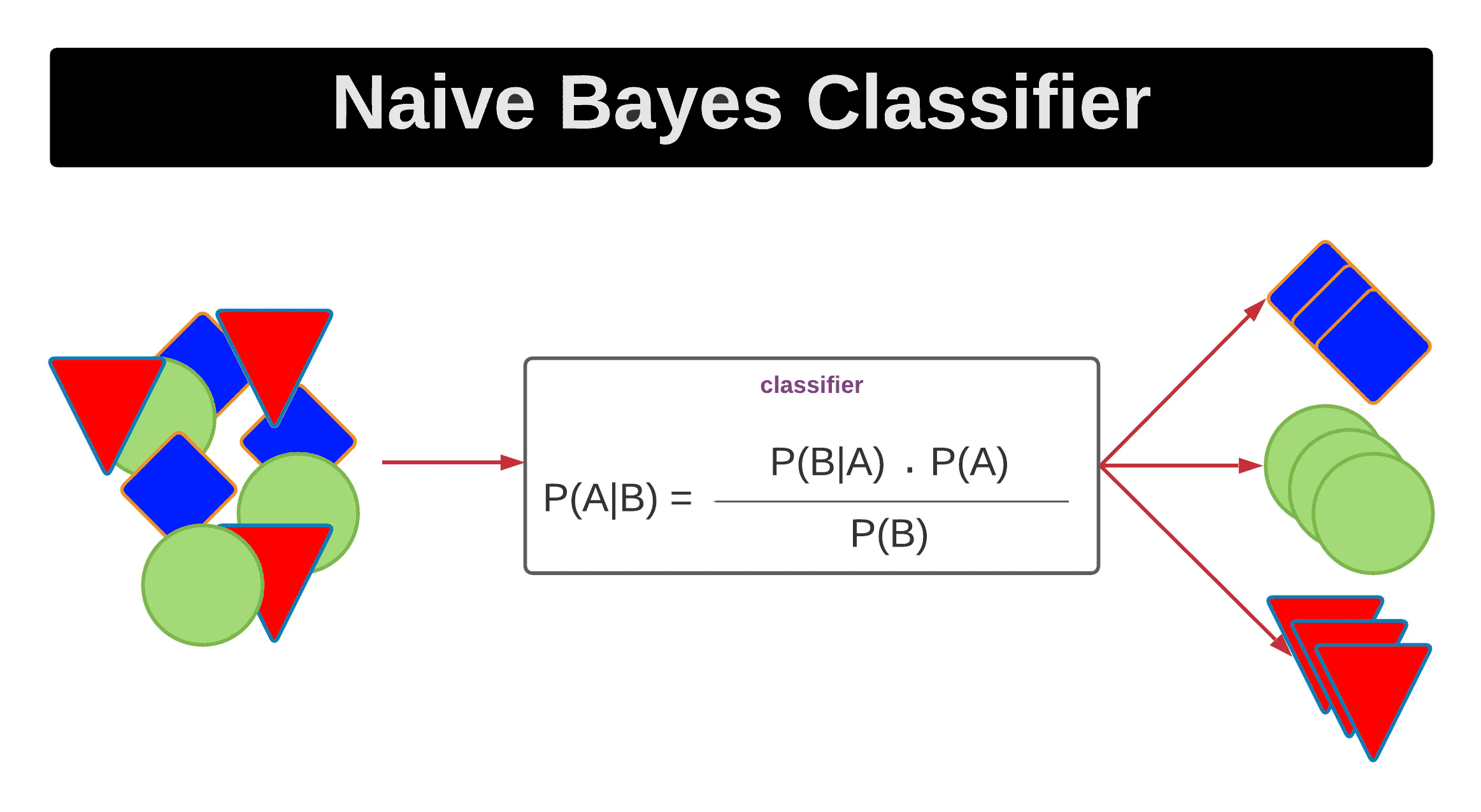
解析:Naive Bayes 假設所有特徵在給定類別情況下互相獨立,儘管實際往往違背,但在多場景也能表現不錯。
79. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
對於時間序列資料,機器學習需要注意什麼?
答案:B
解析:在時間序列中,後期資料往往代表未來,若混進訓練樣本會導致資料洩露。
80. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
若要將文字敘述轉為特徵向量,常用到哪種方法?
答案:C
解析:文字處理需先轉為可數值化的特徵,如 BOW/TF-IDF/embedding 等表示詞語在向量空間的意義。
81. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第140頁)
「過採樣 (Oversampling)」與「下採樣 (Undersampling)」在何種情況下使用?
答案:A
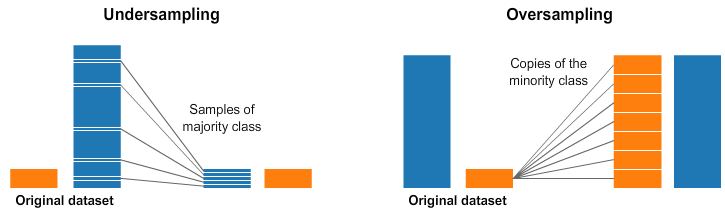
解析:在分類中若正負類極度不平衡,可通過 Oversampling(如 SMOTE)或 Undersampling 調整比例。
82. 出題頻率/重要性:★
由大綱出題:Yes(初級大綱.txt - L11301 機器學習基本原理)
「自動特徵選擇 (Feature Selection)」的目的為?
答案:A
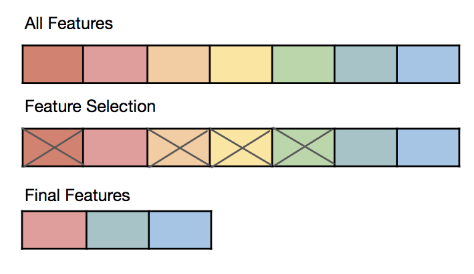
解析:特徵選擇能減少噪音與維度,還能加快訓練速度並降低過擬合。
83. 出題頻率/重要性:★★
由講義出題:Yes(參考:01_AI基礎理論_講義.pdf 第78頁)
「混淆矩陣 (Confusion Matrix)」中,FN (False Negative) 代表?
答案:A
解析:FN=真值Positive,但模型判斷Negative → 屬漏報的情況。
84. 出題頻率/重要性:★★★
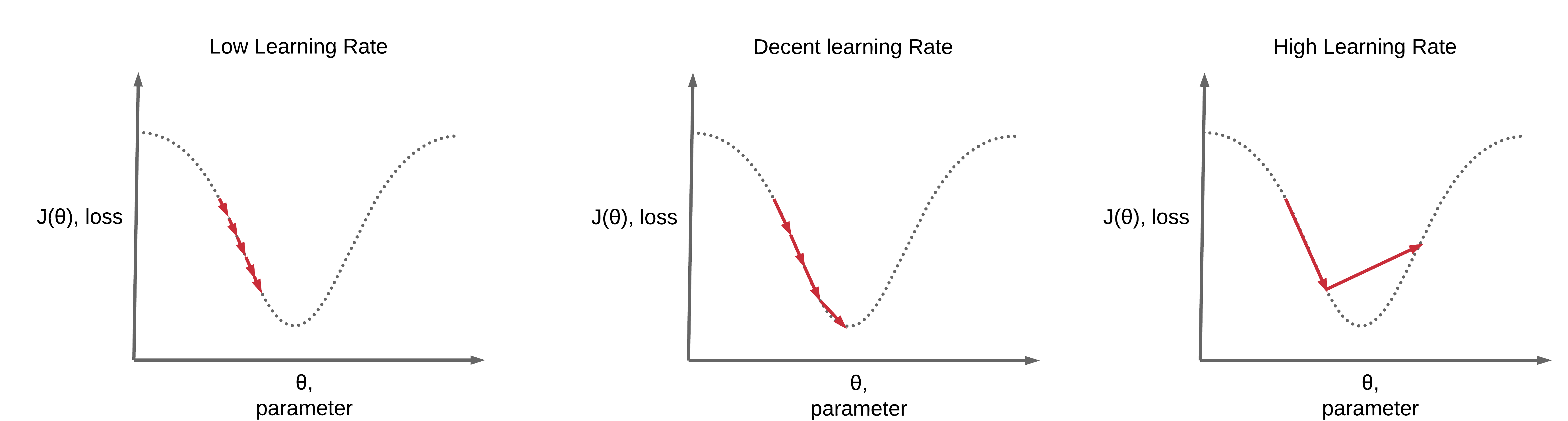
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第150頁)
「Learning Rate Scheduler」可在訓練過程中怎麼運作?
答案:A
 "
"
解析:Scheduler能隨epoch增長自動遞減學習率,或在表現未提升時降低學習率等。
"
85. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
「Ensemble Stacking」與 Bagging/Boosting的差異在於?
答案:A
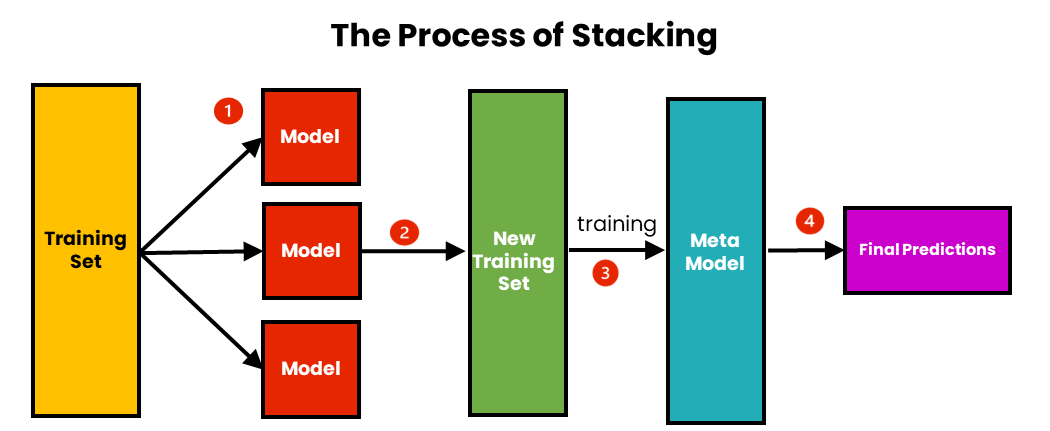
解析:Stacking有「次級學習器」(meta learner)去整合多種模型預測結果;Bagging/Boosting通常同類弱分類器。
86. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
機器學習中,出現「資料洩漏 (Data Leakage)」時會導致?
答案:A
解析:若測試資料在訓練時被用到,模型評估失去公正性,會高估真實表現。
87. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第160頁)
若想同時考慮特徵交互作用,可用哪種方法?
答案:A
解析:可以人工創建交叉特徵(如多項式)或透過樹模型分裂路徑,捕捉特徵之間的交互影響。
88. 出題頻率/重要性:★
由大綱出題:Yes(初級大綱.txt - L11301 機器學習基本原理)
初學者常犯錯之一:直接看訓練集 Accuracy 來評價模型。可能問題是?
答案:A
解析:只看訓練表現會忽視泛化能力,必須檢查測試/驗證集表現才能避免過擬合。
89. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
在影像辨識等領域,通常需要大量標記資料,原因是?
答案:B
解析:如CNN等深度模型參數量大,需龐大訓練樣本提供足夠學習,否則過擬合。
90. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第170頁)
「特徵重要性 (Feature Importance)」在樹模型中如何估算?
答案:A
解析:像Random Forest或XGBoost可根據特徵使不純度或Loss下降量計算重要度。
91. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
當資料中有大量缺失值且分佈不均,常見做法?
答案:A
解析:缺失值處理視比例、分佈與機制而定,可能用均值、中位數、模型預測等方式合理補齊。
92. 出題頻率/重要性:★★
由大綱出題:Yes(初級大綱.txt - L11301 機器學習基本原理)
在模型部署後,為何需要持續監控模型效能?
答案:A
解析:真實世界資料分佈可能漸變(概念漂移),需監控並適時更新模型。
93. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第180頁)
「半監督式學習 (Semi-supervised Learning)」在實務應用中常見於哪種情境?
答案:A
解析:半監督透過無標籤樣本學得分佈結構,再配合少量標籤資料指示,可顯著提升效果。
94. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
要檢驗模型是否「過度依賴個別特徵」或「穩健」,可嘗試什麼測試?
答案:B
解析:若移除或干擾某特徵導致精度顯著下降,代表該特徵對模型決策影響很大。
95. 出題頻率/重要性:★★
由講義出題:No(外部延伸參考)
「One-vs-Rest (OvR)」策略在多類別分類中是如何運作?
答案:A

解析:多分類可透過OvR(或OvO)拆成多個二分類器,再綜合判斷哪類概率最高。
96. 出題頻率/重要性:★★★
由講義出題:Yes(參考:01_AI基礎理論_講義.pdf 第80頁)
機器學習中,為何要做「超參數 (Hyperparameters)」調整?
答案:A
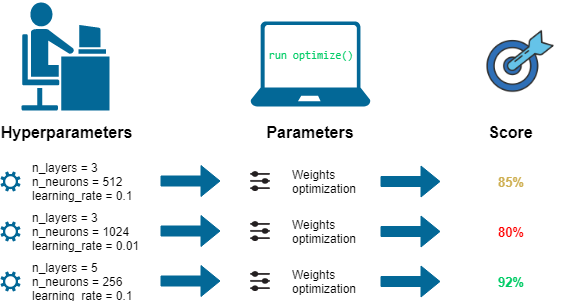
解析:如學習率、正則強度、樹深、K值等屬超參數,不會自動更新,須網格/隨機/貝氏最佳化等。
97. 出題頻率/重要性:★
由講義出題:No(外部延伸參考)
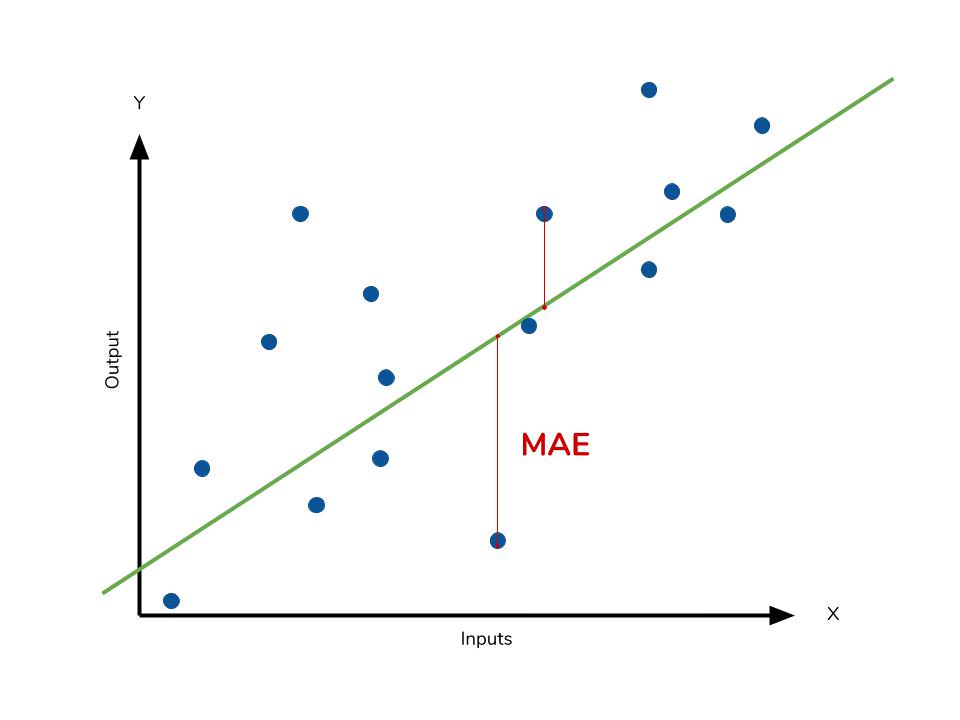
在回歸問題中,若 outlier(極端值)很多,可能優先考慮哪種誤差度量?
答案:A
解析:MAE對outlier較不敏感,MSE則會擴大outlier影響。另Huber也是折衷選項。
98. 出題頻率/重要性:★★
由大綱出題:Yes(初級大綱.txt - L11301 機器學習基本原理)
「資料前處理」對機器學習模型的重要性為何?
答案:A
解析:資料品質與前處理決定模型上限,垃圾進、垃圾出(GIGO)就是其反面案例。
99. 出題頻率/重要性:★★★
由講義出題:Yes(參考:04_機器學習技術理論與案例_講義.pdf 第190頁)
「偏差校正 (Bias Correction)」在某些模型結果中為何需要?
答案:A
解析:如採樣不均或模型系統性誤差,可通過偏差校正(後處理)使分布與真實狀況更一致。
100. 出題頻率/重要性:★★★
由講義出題:Yes(參考:01_AI基礎理論_講義.pdf 第90頁)
綜觀「L11301 機器學習基本原理」後半段要點,下列何者最佳總結?
答案:B
解析:成功機器學習需多層面配合:特徵、演算法、調參、正則與評估迭代,持續維護才能在實務中表現良好。